第十章:支持教师的生成式人工智能工具:与Dorottya Demszky的对话
OECD:您认为生成式人工智能可以为教师提供什么来支持他们的教学和学生的学习,特别是当这些工具面向教师时?
Dora Demszky:我的实验室 EduNLP lab1 主要关注这个问题:包括 GenAI 在内的人工智能工具如何以不同的方式为教师提供支持,当然,这个领域还有更广泛的工具。 GenAI 至少可以在 4 个领域提供支持:课程规划、基于实际教学的专业发展、辅导的实时支持以及向学生和学生提供反馈。
OECD:太好了。让我们依次从课程计划和课程材料的开发开始。
在舞蹈或音乐方面有创造力的学生可能在科学方面没有创造力,反之亦然。他们必须拥有某个领域的知识和经验才能创造出新的、合适的东西
课程规划与课程材料开发
OECD:您提到生成式人工智能在课程规划方面可以支持教师。具体而言,哪些领域最有前景?
Dora Demszky:生成式人工智能在课程规划方面的一个关键应用是帮助教师适应现有课程材料。这不仅仅是简化内容,而是涉及保持严谨性和保留精心设计的专家课程的核心理念。我们的项目ScaffGen研究生成式人工智能如何支持教师进行课程改编,同时考虑高质量的教学材料和教师特定的情境,例如学生低于年级预期熟练水平的情况。这涉及帮助教师为学生改编和创建支架,同时确保这些支架与课程保持一致。
具体领域包括创建更多练习任务和生成可视化辅助材料,例如同一问题的不同表示方式。我们专注于生成式人工智能擅长的多模态生成,目前使用LaTeX生成图表。我们已经评估了大语言模型为高质量教学材料生成的支架,并与专家创建的支架进行了比较。我们发现,大语言模型生成的支架与专家创建的支架质量相当,教师有时甚至更偏好大语言模型生成的支架,这显示了良好的前景。但仍存在差距,特别是在可视化辅助材料生成方面。另一篇即将发表的论文是一个基准研究,包含来自美国领先K-12数学课程“说明性数学”(Illustrative Mathematics)的数千个图表和LaTeX代码数据集。我们将发布这个数据集和基准研究,以了解人工智能在这一领域的表现。
OECD:我们对人工智能生成的课程计划以及您的图表生成工具的功效有什么了解?
Dora Demszky:我的一位往届学生开发了CoTeach.AI,这是一款基于说明性数学课程的人工智能课程改编工具。在短短一周的小规模试点推广后,该工具已获得显著关注,拥有数千名常规用户。我们估计,目前使用说明性数学的教师中约有10%使用CoTeach.AI,这一比例相当可观。关于功效,我们正在进行研究,并计划围绕图表生成工具开展试点。我们将测试使用该工具的教师与不使用该工具的教师所生成课程计划的质量,特别关注多重表示的理念。我们希望了解该工具生成图表的能力是否有助于学生理解不同表示之间的联系(例如,可视化抽象分数)。课程提供的表示方式有限,我们相信我们的工具可以极大地支持教师在这方面的工作。
更一般地说,我尚未看到针对更广泛课程规划工具(如MagicSchool或School.ai)功效的任何研究。大部分都是自我报告的使用情况或感知评估。评估功效具有挑战性,因为它需要严格的课程计划质量指标,理想情况下还需要衡量学生成果。收集学生成果数据缓慢、昂贵且在后勤上困难,这通常需要研究人员来做,因为教育技术行业缺乏相关激励机制。我们正在努力解决这个问题,但这是一个缓慢的过程。
OECD:我也不知道有任何关于课程计划对学生学习功效的研究。一些研究通过人工判断和节省的时间来评估生成的课程计划质量,侧重于生产力而非课程是否带来更好的教学质素。看起来您的ScaffGen比完整的课程计划更加精细。
Dora Demszky:CoTeach可以生成完整的课程计划,但通常它生成的是活动。作为ScaffGen项目的一部分,我的实验室专注于许多行业提供商缺乏带宽进行的核心研发工作,例如图表生成,这需要精心的工程设计、评估、基准测试和基础设施。许多现有工具本质上是大型语言模型的包装器,即围绕大型语言模型构建的软件层或接口:它们没有能力构建这些具有挑战性但必要的功能。我们专注于基础技术和评估,尽管后者很复杂,需要合作伙伴关系。我们正在为功效研究制定课程计划质量评估标准。在伦理上,从对照组教师那里扣留此类工具也具有挑战性。尽管存在这些悬而未决的问题,我们有兴趣收集证据。
OECD:您提到教师有时更偏好大型语言模型的反馈而不是专家的反馈:您能详细说明吗?
Dora Demszky:在2023年的一个项目中,我们使用比当前模型更早的大型语言模型,根据预定义的维度评估课程计划质量,如课堂使用的准备度、与课程目标的契合度、偏好程度以及与学生需求的契合度。教师将说明性数学的原始课程热身活动与两种不同的大型语言模型生成和专家生成的课程计划进行比较。在所有标准上,大语言模型和专家生成的内容都比原始材料更受欢迎,且幅度很大。在某些维度上,大语言模型甚至优于专家。这很有前景,但需要仔细解读。
课堂分析
OECD:您提到的第二个应用属于“课堂分析”类别,支持教师专业发展或实时课堂组织。我一直觉得这是人工智能的一个迷人且有前景的应用。生成式人工智能为这些人工智能工具带来了什么?
Dora Demszky:生成式人工智能可以支持教师使用教学上合理的“言语移动”和话语实践,这些实践探究学生的思维,而不是仅仅引导他们找到预设的解决方案或反复练习。这涉及鼓励学生表达的对话语实践。生成式人工智能可以帮助分析课堂话语和学生互动。这可以在课后进行:物理或在线课程结束后,转录文本被分析,生成式人工智能(或更简单的人工智能模型)可以提供明确的建议,说明如何改进教学实践,或下一次尝试哪些言语移动来支持主动学习。
我们已经进行了超过4项随机对照试验,测试这种自动化的课后反馈如何支持教学改进。我们有一个名为“赋能教师”(Empowering Teachers)的工具。教师授课后,他们会收到一份报告或反馈,重点关注不同的言语移动,例如邀请学生思考。报告包含计数和说话时间。ChatGPT的建议也包含在论文中。这些言语移动是通过基于语言模型的分类器检测的,而非生成式人工智能本身。
我们发现,收到分类器自动反馈的教师在仅两次反馈后,使用目标言语移动(例如,聚焦问题、在学生想法基础上继续或引出学生想法)的频率比未收到此类反馈的对照组高出最多20%。一个局限性是缺乏对学生学习成果的严格评估,但我们可以使用学生参与度指标,如更多发言、上课出勤和完成作业。我们发现,收到此类反馈的教师的学生更有可能提交作业和上课。
仍有改进空间,但这是很有前景的。生成式人工智能擅长总结对话,但难以准确识别高杠杆教学实践,因为这需要大量课堂背景和理解。即使仔细设计提示,它有时也会产生幻觉或错误分类课堂互动。不过,我们看到这个领域有很大潜力,特别是对于志愿者导师或接受培训有限的新教师等新手而言。这将为他们提供专业学习机会。
我看到的行业活动在言语移动建议方面较少,也许是因为利润较低。更常见的是像Khanmigo这样的全自动辅导系统,尽管其有效性仍需证据。我们的实验室专注于支持人类导师和教师,因此我们开发和研究这些面向教师的工具。
OECD:教师对这些工具的接受程度如何?采用通常是这些问题之一。
Dora Demszky:一个实际挑战是一些教师发现很难根据这些反馈采取行动。这需要反思,因此需要时间。虽然它提高了意识,但深度改变通常更好地由人类教练支持。我们刚刚发表了一篇工作论文,其中教学教练帮助教师解读这些反馈,这非常有帮助。教练支持提取具体证据,教师因为与教练一起查看第三方证据而感到较少的评判。
实时支持
OECD:您一项非常有趣的研究是关于为人类导师提供实时支持。您能告诉我们这项研究吗?
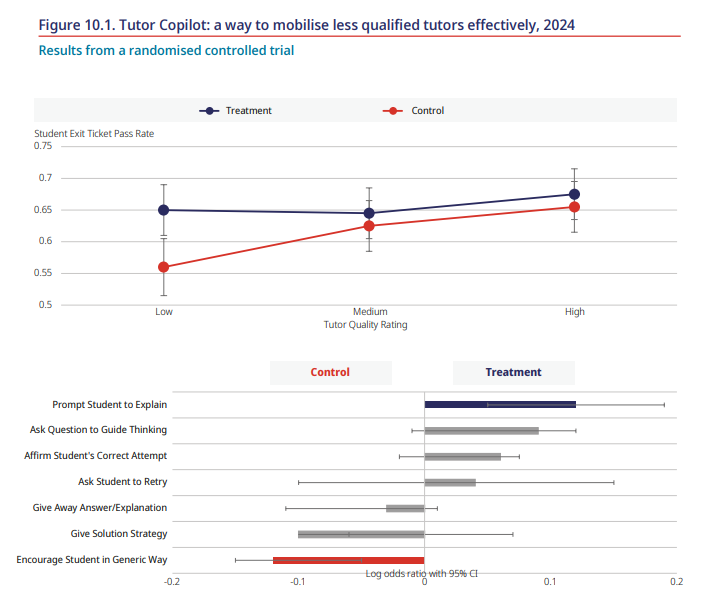
Dora Demszky:是的,在实时建议领域,我们有Tutor Copilot项目,这是与斯坦福大学SCALE的合作项目。该项目与一个支持低收入学生的基于文本的校内辅导服务提供商合作。Tutor Copilot允许导师在在线辅导过程中,当学生出现数学错误并需要补救时激活该工具。它建议不同的应对策略和实际可编辑的回复,赋予导师自主权,同时也具有教育目的。一项随机对照试验表明,有机会使用Tutor Copilot的导师使用了更好的教学实践,他们的学生更快掌握课程。这对于初始质量评级较低或经验较少的导师特别有帮助(见图10.1)。
图10.1 Tutor Copilot:有效调动素质较低导师的方式,2024年
随机对照试验结果
学生出门票通过率
0.75(处理组)、0.7、0.65、0.6、0.55、0.5(对照组)
横轴:低、中、高 导师质量评级
分组:对照组、处理组
测评维度:引导学生解释、提问引导思考、肯定学生的正确尝试、让学生重试、直接给出答案/解释、给出解题策略、以一般方式鼓励学生
数值区间:-0.2、-0.1、0、0.1、0.2(优势比的自然对数,95%置信区间)
注释:这两张图显示了使用Tutor CoPilot对学生学习(上图)和导师教学方法(下图)的结果。对学生学习的影响因导师的初始有效性(按质量评级衡量)而异。结果表明,对初始有效性较低的导师有实质性益处。评级较低的导师的学生通过率从对照组到处理组增加了9个百分点(56%增加到65%)。在经验较少的导师中也观察到类似的效果。
下图显示了一些教学策略可能被对照组导师(左)与处理组导师(右)使用的情况。z分数低于1个标准差的策略以灰色阴影显示。对照组导师倾向于依赖解决方案导向、被动的策略,而处理组导师更频繁地使用促进学生更深度参与和理解的策略。
来源:Wang et al. (2025[1]), Tutor CoPilot: A Human-AI Approach for Scaling Real-Time Expertise, Retrieved from Annenberg Institute at Brown University, https://doi.org/10.26300/81nh-8262.
OECD:您认为选择通用大型语言模型与更具教育针对性的模型哪个更合适?您如何确保生成式人工智能的使用在教育上是适当的?
Dora Demszky:这是一个非常大的问题,这也是我们向教师提出的核心问题之一。教师如何确定适当性?特定模型(GPT、Cloud、Gemini)不断变化,我们没有发现巨大差异。最佳模型可能下周就会改变……教育适当性的标准因背景、教师和项目而异。了解这些标准很重要。我们今年夏天在斯坦福大学为数学教育者举办了一场“实践者之声”峰会,我们的主要目标之一是了解他们评估人工智能工具的标准。我们的简短报告可以在网上找到,我们将在近期发布一篇更长的论文。
OECD:在Tutor Copilot案例中,系统是通过基于对专家教师的观察和工作提供的数据进行训练的。您认为,如果没有这种专门的教育元素,当时的GPT-4是否会产生类似的结果?
Dora Demszky:不能,我们明确需要专家教师的输入来改进模型。如果没有这种“专家知情的认知任务分析”——即我们告诉模型专家教师如何补救学生的错误——它的表现会明显差很多。我们在ScaffGen中正在进行类似的工作,给予模型这些专家知情的流程。这与判断工具是否良好的评估标准相关,但略有不同,尽管两者可以相互借鉴。
OECD:这些工具能否补充和增强教师以提高教育质量,特别是在教师短缺或缺乏专业知识的教师的国家或环境中?
Dora Demszky:我想对“我们没有可用的人类教师”这一前提提出质疑。接受技术应该(或能够)取代人类教师角色是危险的,因为这可能会加剧获得人类教师机会的不平等,不仅在低收入国家,在美国和经合组织国家内部也是如此。如果情况确实缺乏人类教师,我们必须仔细考虑这些工具可以履行哪些角色。建立关系的部分不能被技术取代,尽管其他方面可能可以被取代,这仍有待测试。
OECD:我不是在考虑取代教师,而是更多地说,如果您有缺乏经验的教师或低质量教师,或者缺乏学科和教学法知识的人,这些工具能否帮助他们提高表现?在许多国家,培训这么多教师是不现实的,因此能够招募下一人来辅导或教学可能会有所帮助。如果人类还不知道自己在做什么,像Tutor Copilot这样的工具能提供帮助吗?
Dora Demszky:这些技术的核心关注点不是节省时间,而是教育元素——支持教师的专业学习。所有教师都有成长空间。不同版本的工具可以根据用户的经验水平进行定制;例如,新手教师可能在获得更多培训之前会被太多的决策或信息所淹没。我们用完全的新手测试了一些工具。在斯坦福大学举办的全球编程课程“Code in Place”中,我们为数以千计的志愿者分组成员实施了教师反馈工具,他们中的大多数人几乎没有教学经验。这个反馈工具对他们有帮助,因此这是一个我们正在瞄准的重要用户群体。但如果我们要在您提到的环境中使用这些技术,我们需要进行前期工作以确保这些技术能够转化为不同的语言和本地需求。
OECD:您认为生成式人工智能有什么是永远无法像人类一样做得好的吗,如果有的话,特别是在教育中的人文维度方面?
Dora Demszky:积极性和建立关系是生成式人工智能可能永远无法像人类做得一样好的关键要素。虽然需要更多的研究,但教育专家达成共识,这也很直观。人工智能不会被视为榜样。学生可能会与人工智能分享他们不会与人类分享的事情,因为他们不那么害怕脆弱。然而,人类能够更好地支持情感福祉并创造责任感。对于人工智能,没有责任感。学生可能不会关心他们做什么,因为人工智能不会受伤。例如,社会情感技能在与人类教师和人类同伴一起学习时会学得更好。学习涉及的远不止知识或信息收集。
学生作业反馈
OECD:让我们转向您最初提到的最后一个领域:对学生的反馈。我们知道这对学生学习至关重要,对于教师我们已经提到过,对学生也是如此。生成式人工智能能提供什么?
Dora Demszky:教师对学生作业提供反馈是行业和学术界的一个重研究和发展领域。教师通常缺乏时间(想象他们有150名学生),也缺乏提供高质量反馈的培训。当我们的目标不仅仅是生产力和节省时间时,专注于提高教学质量和反馈质量至关重要。一些工具已经存在,如Brisk,支持生成式人工智能驱动的反馈,特别是在写作方面。我们正在开发经过严格验证的工具,同时也支持反馈提供的专业学习。
OECD:您是说形成性评估,即对学生的书面作业提供反馈吗?还是与您告诉我们关于实时反馈和对话实践的应用有关?这两个如何联系,我们对这些正在开发的工具的功效了解多少?
Dora Demszky:我们的工作集中在教师可以对学生的作业提供的形成性反馈上,但强调修改。反馈的目的之一是帮助学生改进和修改他们的作业,如果学生没有机会修改,他们不太可能阅读反馈。我们专注于学生有改进空间和风险较低的领域。这些新反馈工具的功效仍有待观察,因为它们非常新,但概念上设计似乎是合理的。
教师通常不加编辑地接受生成式人工智能的建议。这是一个问题。我们明确设计工具是为了支持教师创建反馈,而不是取代他们的反馈,因为研究表明,学生不太可能对被感知为来自人工智能而不是教师的反馈采取行动。对学生来说,感受反馈来自他们的教师至关重要。我们正在开发反馈质量基准,这是一套评估教师或人工智能工具反馈的指标,我们希望行业能够采用。
我们有一篇工作论文,比较了专家撰写的反馈与大语言模型生成的反馈。虽然大语言模型不差,但在关键领域明显落后于专家。例如,大语言模型的对话性要低得多,往往给出具体的重写建议(“这个不对,这里是如何改写”),而不是参与整体论证或探究学生思维以鼓励修改。此外,大语言模型的评论可能不连贯,不像教师的连贯反馈,后者是相互构建的。我们正在积极努力改进和评估生成式人工智能工具的使用。
两个项目线——面向教师的言语反馈(专注于数学/STEM)和面向学生的写作反馈——目前没有直接联系。然而,我们设想整合它们。例如,教师可以收到课后报告,总结学生作业和课堂讨论,为作业提供反馈建议,并指导未来的课程计划。这可能是一条互补的系统路线。
现实实施
OECD:那么,您提到的所有工具都可以在现实生活中的课堂或教学环境中使用,除了Tutor Copilot用于虚拟平台?例如,您能想到在面对面环境中使用Tutor Copilot吗?
Dora Demszky:我们需要谨慎,不要让实时建议工具在虚拟或物理面对面环境中分散注意力,也不要剥夺教育者的自主权。我们正在探索的一个想法是,在实时课堂的高杠杆时刻呈现反馈,例如当学生正在解决问题并且出现停顿时,而不是不断给出建议。识别这些不分散注意力的时段可能非常有用。
在虚拟环境中这是直接的;您可以推测这些时刻何时可能发生并呈现反馈。在物理课堂中,由于准确捕捉学生声音、向教师呈现实时反馈(例如通过iPad)和仪器化的挑战,这更加困难。我们需要与教师讨论这个问题。我们“实践者之声”峰会参与者的一个问题是这些工具如何在物理课堂中支持教师,是否通过分析小组工作或教师话语。他们可能帮助我们设想实际实施。可能存在差异,有些教师更喜欢课后反馈,有些则欣赏实时工具。我们的更长的报告将报告我们从教师那里学到的东西。
注释
1. https://edunlp.stanford.edu/
2. https://hai.stanford.edu/news/how-math-teachers-are-making-decisions-about-using-ai
延伸阅读文献
Demszky, D., H.C. Hill, E.S. Taylor, A. Kupor, D. V. Dennison and C. Piech (2025), “Does Increased Agency Improve the Effectiveness of Self-Directed Professional Learning for Educators?”, EdWorkingPaper No. 25-1162, Annenberg Institute for School Reform at Brown University, https://doi.org/10.26300/04kc-7085.
Demszky, D., J. Liu, H.C. Hill, D. Jurafsky and C. Piech (2024), “Can automated feedback improve teachers’ uptake of student ideas? Evidence from a randomized controlled trial in a large-scale online course”, Educational Evaluation and Policy Analysis, Vol. 46(3), pp. 483-505, https://doi.org/10.3102/01623737231169270.
Demszky, D. and J. Liu (2023), M-Powering Teachers: Natural Language Processing Powered Feedback Improves 1: 1 Instruction and Student Outcomes, https://doi.org/10.26300/s8xh-zp45.
Demszky, D., J. Liu, H.C. Hill, S. Sanghi and A. Chung (2025), “Automated feedback improves teachers’ questioning quality in brick-and-mortar classrooms: Opportunities for further enhancement”, Computers & Education, Vol. 227, https://doi.org/10.1016/j.compedu.2024.105183.
Demszky, D., R. Wang, S. Geraghty, and C. Yu (2024), “Does Feedback on Talk Time Increase Student Engagement? Evidence from a Randomized Controlled Trial on a Math Tutoring Platform”, Proceedings of the 14th Learning Analytics and Knowledge Conference, pp. 632-644, https://doi.org/10.1145/3636555.3636924.
Handa, K., M. Clapper, J. Boyle, R. Wang, D. Yang, D.S. Yeager, and D. Demszky (2023), “Mistakes Help Us Grow”: Facilitating and Evaluating Growth Mindset Supportive Language in Classrooms, https://doi.org/10.18653/v1/2023.emnlp-main.549.
Mah, C., M. Tan, L. Phalen, A. Sparks, and D. Demszky (2025), “From Sentence-Corrections to Deeper Dialogue: Qualitative Insights from LLM and Teacher Feedback on Student Writing”, EdWorkingPaper: 25-1193, Retrieved from Annenberg Institute at Brown University, https://doi.org/10.26300/p397-2p46.
Malamut, J., D. Demszky, C. Bywater, M. Reinhart, H.C. Hill (2025), Facilitating Evidence-Based Instructional Coaching With Automated Feedback on Teacher Discourse, Retrieved from Annenberg Institute at Brown University, https://doi.org/10.26300/xx9z-8f27.
Malik, R., D. Abdi, R. Wang, and D. Demszky (2025), “Scaffolding middle school mathematics curricula with large language models”, British Journal of Educational Technology, Vol. 56/3, pp. 999-1027, https://doi.org/10.1111/bjet.13571.
Malik, R., D. Abdi, R. Wang, and D. Demszky (2024), “Scaling High-Leverage Curriculum Scaffolding in Middle-School Mathematics”, Proceedings of the Eleventh ACM Conference on Learning @ Scale, pp. 476-480, https://doi.org/10.1145/3657604.3664698.
Malik, R., R. L. Hao, R. Kacholia, and D. Demszky (2025), “MathemaTikZ: A Dataset and Benchmark for Mathematical Diagram Generation”, Proceedings of the Twelfth ACM Conference on Learning @ Scale, pp. 95-104, https://doi.org/10.1145/3698205.3729558.
Wang, R. and D. Demszky (2023), Is ChatGPT a Good Teacher Coach? Measuring Zero-Shot Performance for Scoring and Providing Actionable Insights on Classroom Instruction, https://doi.org/10.18653/v1/2023.bea-1.53.
Wang, R., A.T. Ribeiro, C.D. Robinson, S. Loeb, and D. Demszky (2025), Tutor CoPilot: A Human-AI Approach for Scaling Real-Time Expertise, Retrieved from Annenberg Institute at Brown University, https://doi.org/10.26300/81nh-8262.
Wang, R., Q. Zhang, C. Robinson, S. Loeb, and D. Demszky (2023), Bridging the Novice-Expert Gap via Models of Decision-Making: A Case Study on Remediating Math Mistakes, https://doi.org/10.48550/arXiv.2310.10648.