第十三章:生成式人工智能与科学研究的转型
引言
随着时间的推移,科学进步的特点是使用越来越多的数据来解决日益复杂的问题。此外,科学家们一直在使用功能日益强大的仪器来补充人类大脑和感官,例如显微镜、医学成像设备或粒子加速器。书写、印刷和现在的计算机也使科学家能够存储、分析和交流科学信息。人工智能(AI)的最新代表是生成式人工智能(GenAI),它是科学仪器历史趋势的又一步,它允许以新的方式处理大量复杂的数据。
科学研究一直处于人工智能应用的最前沿,GenAI 的到来进一步加速了人工智能的使用,让所有科学家都能更容易地使用它。最近的调查表明,现在有超过一半的科学家使用 GenAI 工具。GenAI 可以分析和生成结构化和非结构化数据,包括文本、表格、统计数据、图像、视频、图表、图表、化学和数学公式、DNA 序列和其他生物数据。它可以通过基于训练数据学习和重新组合模式来生成具有特定属性的新数据;例如,对问题的回答、合成数据集、模拟或天气预报等预测,甚至模拟代理。GenAI 帮助研究人员加速现有的研究任务(例如编写文本和统计处理)、提高其他任务的质量(例如编辑和生成图表)以及执行以前无法完成的任务(例如分析极大的数据集)。为了帮助完成这些任务,GenAI 正在改变科学研究。
本章将首先概述人工智能在科学中的各种用途,并强调这些用途与教育研究的相关程度。由于教育研究涉及许多学科(Vincent-Lancrin 和 Jacotin,2023[1]),了解 GenAI 如何在各种学科中使用将有助于政府研究资助者设想即将到来的 Dominique Guellec* 和 Stéphan Vincent-Lancrin** *法国科学技术观察站 **OECD教育研究的变化。然后,本章将研究人工智能对研究创造力和科学可靠性的可能影响,这两个问题在科学界备受争议,并且与教育有直接联系。结论将探讨使用 GenAI 进行教育研究可能产生的一些后果。
生成式人工智能在科学研究中的应用
生成式人工智能在研究中有四个不同但相互关联的用途:处理语言(包括科学语言);管理知识;生成知识;以及管理研究项目整个操作链条。因此,用于研究的生成式人工智能模型可分为四类:1)通用模型,特别是大型语言模型(LLM)——如GPT、Gemini等——被许多研究人员用于生成文本、图像或计算机代码;2)专用模型,专注于管理各种语言相关任务,如文献综述、同行评议和假设生成或实验建议(”构思”);3)专用模型,用于处理涉及大量数据或复杂机制的极高复杂度科学问题(例如,蛋白质的三维结构);4)研究助手和”机器人实验室”,自主管理研究项目的整个操作序列,从初步数据分析到实验操作。以下将在介绍生成式人工智能在研究人员中传播的证据之后,依次考察这四类模型。一个清晰的趋势将随之呈现:生成式人工智能的认知能力和自主性随时间不断提升。
生成式人工智能在研究中的应用进展迅速,但统计数据仍然有限。更广泛的人工智能采用趋势有助于指示未来的生成式人工智能模式。
人工智能的采用一直在快速推进。Duede等人(2024[2])追踪了人工智能参与出版物的份额(1985-2022年),在所有科学领域从2015年的约2%上升到2022年的8%(图13.1)。Evans等人(2024[3])分析了1亿篇论文(1980-2024年),识别出超过100万篇人工智能辅助论文(总体占1.57%),显示出在生物学、医学、化学、物理学、材料科学和地质学中的普及。
图13.1 所有科学领域人工智能参与度的变化
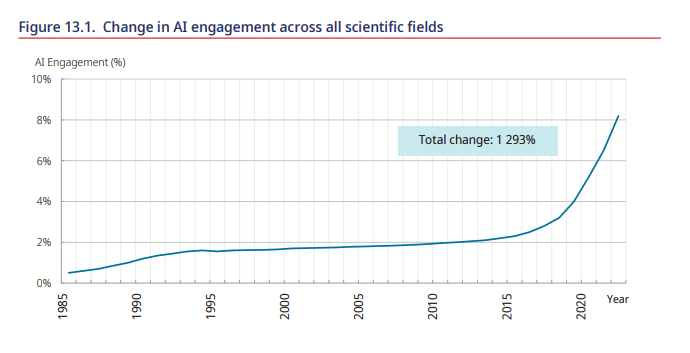
人工智能参与度(%)
10%
8%
6%
4%
2%
0%
1989 1991 1995 1999 2001 2005 2009 2011 2015 2017 2019 2021 2023
年份
总变化:1293%
来源:Duede, E., W. Dolan, A. Bauer, I. Foster and K. Lakhani, (2024[2]), Oil & Water? Diffusion of AI Within and Across Scientific Fields.
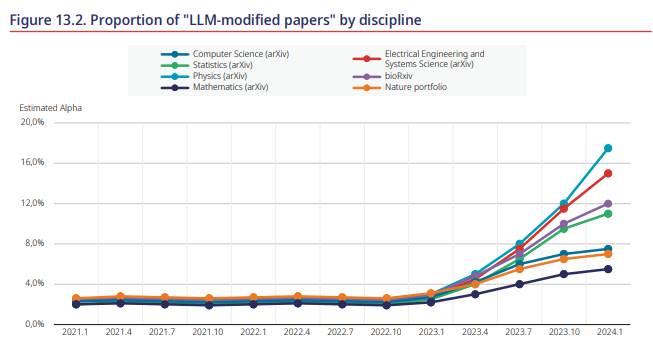
就生成式人工智能而言,Liang等人(2024[4])研究了2020-2024年间近100万篇论文,发现”大型语言模型修改”论文稳步增长,在ChatGPT发布后增幅最为陡峭。采用率在计算机科学中最高(17.5%),在数学中最低(6.3%)(图13.2)。该分析不包括社会科学,而社会科学是教育研究的主要贡献者之一,尽管自然科学在教育研究产出中占有重要 minority(Vincent-Lancrin and Jacotin, 2023[1])。
© OECD 2026 OECD《数字教育展望2026》
221
图13.2 各学科“大型语言模型修改论文“的比例
计算机科学(arXiv)
统计学(arXiv)
物理学(arXiv)
数学(arXiv)
电气工程与系统科学(arXiv)
bioRxiv
自然系列
估计Alpha值
20.0%
16.0%
12.0%
8.0%
4.0%
0.0%
2021.1 2021.4 2021.7 2021.10 2022.1 2022.4 2022.7 2022.10 2023.1 2023.4 2023.7 2023.10 2024.1
1月 4月 7月 10月 1月 4月 7月 10月 1月 4月 7月 10月 1月
来源:Liang et al. (2024[4]), Can large language models provide useful feedback on research papers? A large-scale empirical analysis, https://arxiv.org/abs/2310.01783.
一项调查(2025年3月进行,调查对象为5000名研究人员)估计,超过半数的研究人员已使用人工智能进行手稿准备和错误检测(Naddaf, 2025[6])。约三分之一使用或计划使用生成式人工智能进行数据收集/处理,而将其用于复杂任务(期刊选择、引用管理)的比例则较低。超过半数的受访者认为,人工智能在文献综述、摘要生成、抄袭检测和引用管理等方面的表现优于人类,预计将在两年内成为主流应用(图13.3)。职业早期研究人员比资深同事表现出更高的热情,尽管许多人对人工智能在高级任务中的作用仍持谨慎态度。尽管各领域存在差异,可以假设这些主要语言相关任务的应用率在教育研究人员中相似。
第一类应用与语言相关:翻译、编辑、撰写和总结论文。这些任务通常涉及通用大型语言模型(ChatGPT、Claude、Gemini等),这些模型最容易获取,但并非唯一,因为一些专业科学工具也具备此类功能。人工智能可以帮助调整论文以符合期刊投稿指南、撰写摘要、撰写同行评议以及协助撰写资助提案(Heidt, 2025[7])。尽管研究人员已经在使用一些人工智能写作助手,但大型语言模型的发布带来了此类应用范围的实质性变化(Lenharo, 2024[8])。
人工智能模型根据研究人员给出的查询(”提示”)生成文本。以下是一个提示示例:”我正在为一家领先的[学科]学术期刊撰写一篇关于[主题]的论文。以下段落我想表达的核心观点是[具体观点],请为清晰性、连贯性和简洁性进行改写,确保每个段落自然衔接。去除行话,使用专业语气。”(Gruda, 2024[9])
机器辅助编辑对于非英语母语者尤其有用,因为它有可能改善流畅性、语法和语气。在欧洲研究委员会(ERC)的一项调查中,超过1000名ERC资助接受者中有75%认为,到2030年,生成式人工智能将减少研究中的语言障碍(Prillaman, 2024[10])。
《自然》杂志的一项调查(Kwon, 2025[11])于2025年3月对全球5000多名研究人员进行了调查(中国代表性不足)。超过90%的受访者表示,使用生成式人工智能编辑或翻译自己的研究论文是可以接受的。当涉及使用人工智能生成文本时——例如撰写整篇或部分论文——多数人(65%)认为这在伦理上是可以接受的,但约三分之一持反对意见。最常见的应用是编辑研究论文,但只有约28%的人表示自己这样做过。对于撰写初稿、总结其他文章供自己论文使用、翻译论文和支持同行评议,这一比例下降到约8%。在撰写初稿方面,42%的博士生报告使用人工智能,而资深研究人员的这一比例降至22%。
222
OECD《数字教育展望2026》 © OECD 2026
图13.3 研究人员对人工智能的使用情况,2025年
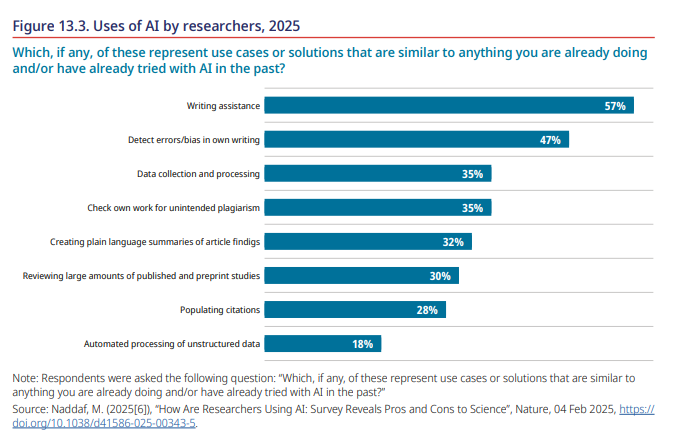
“以下哪些用例或解决方案与您已经做过和/或曾经尝试过的人工智能应用相似?”
写作辅助 57%
检测自己写作中的错误/偏见 47%
数据收集和处理 35%
检查自己作品中的意外抄袭 35%
为文章发现创建通俗语言摘要 32%
审查大量已发表和预印本研究 30%
填充引用 28%
自动化处理非结构化数据 18%
注:受访者被问及以下问题:”以下哪些用例或解决方案与您已经做过和/或曾经尝试过的人工智能应用相似?”
来源:Naddaf, M. (2025[6]), “How Are Researchers Using AI: Survey Reveals Pros and Cons to Science”, Nature, 04 Feb 2025, https://doi.org/10.1038/d41586-025-00343-5.
Kobak等人(2025[12])的研究发现,在2024年发表的生物医学摘要中(150万篇被PubMed索引的论文),有七分之一是由人工智能辅助撰写的。他们通过识别”多余词汇”来检测此类摘要,即自大型语言模型兴起以来频率激增但没有功能作用的词汇(例如,”delve”、”unparalleled”;共计454个多余词汇)。
人工智能写作支持可以为研究人员提高某些非核心任务的 productivity,如润色风格或处理行政事务,从而将时间释放出来用于更具概念性的工作(Gruda, 2024[9])。
专用模型(如Black Spatula项目和YesNoError)用于发现研究论文中的错误,包括事实错误、计算错误、方法缺陷和引用问题。
这些系统首先从论文中提取信息,包括表格和图像。然后,它们制作一个提示,告诉”推理”模型——一种专用的大型语言模型——它在看什么以及要查找哪些类型的错误。该模型可能多次分析一篇论文,每次扫描不同类型的错误或交叉检查结果。然而,误报率——即人工智能声称有错误而实际上没有的情况——是一个主要障碍(根据一些测试,平均为10%;例如,模型可能声称文本中提到的图表实际上不存在于论文中)(Gibney, 2025[13])。
随着科学日益定量化,编程和数据分析成为许多研究人员的核心任务(尤其是博士生),涵盖所有学科(越来越多地包括人文学科)。在教育研究中肯定也是如此,在过去几十年中定量研究的份额有所增加,尽管它仍然只是教育研究的一小部分(Vincent-Lancrin and Jacotin, 2023[1])。这些任务需要复杂技术的特定技能,并且可能耗费大量时间(例如,用于”调试”,即跟踪计算机代码中的错误),同时使研究人员面临重大的错误风险。已经开发了基于生成式人工智能等技术的专用工具来减轻这些负担。
代码编辑器是旨在使研究人员更容易使用代码来组织数据、创建分析序列、生成描述性统计或可视化的工具。此类工具现已广泛普及,已超过GitHub和Stack(一个社区网站)成为故障排除的首选。这些工具允许研究人员节省大量时间,生成更高质量的输出,并将时间分配给更具实质性的事务。用户不必花数小时等待回复者的答案,只需突出显示一段代码,让生成式人工智能聊天机器人修复它(Heidt, 2025[7])。
还有更复杂的人工智能模型,可以对大型数字表格进行广泛分析,并生成预测(插补)、错误检测等输出,从而避免研究人员自己编程的需要。例如,TabPFN是一个”表格机器学习”模型,可以从任何类型数据的表格中进行推理。它可以获取用户的数据集并立即对新数据点进行推断(McElfresh, 2025[14])。
生成式人工智能模型还具有处理”非结构化数据”(如文本和图像)的强大能力,从而可以将其量化并接受强大的统计处理:对于人文和教育研究来说,这显然具有特殊意义。
虽然大型语言模型处理文字,但基于相同技术(特别是所谓的”transformer”架构)的模型可以使用其他类型的数据进行训练:化学公式、数学概念、天文图像、脱氧核糖核酸等。这些模型还可以将不同类型的数据混合作为输入(”多模态”),或者以一种类型的数据作为输入,以不同类型的数据作为输出。数据类型的多样化使得生成式人工智能模型可以应用于各种学科和背景下的广泛问题。
这些模型通常应用于所谓的”封闭世界问题”,其中基本规律是已知的,但由于参数和变量过多,或者关系复杂且非线性,得出预测在计算上很困难。生物化学、材料科学或天气预报中有大量此类例子。这允许将基本的、已建立的知识与算法在数据中发现有意义关联的卓越能力相结合。这些模型本质上是统计性的,因此需要大量数据进行训练,这限制了其适用范围(并非所有领域都提供足够数量的数据)。
这些模型使研究人员能够节省时间并降低研究成本。”我们的目标,”一位生物学家说,”是创建计算工具,使细胞生物学从90%实验和10%计算转变为相反的状态。”这一评论是在一个使用人工智能创建”虚拟细胞”的项目背景下做出的(Callaway, 2025[15])。
虽然教育系统产生大量数据,但隐私和伦理问题使其在教育研究中的广泛应用变得复杂。尽管如此,其中一些技术可能越来越多地应用于大型数据分析,并且已经在一定程度上使用。例如,Pardos和Borchers(2026[16])使用这些人工智能分析和可视化工具,根据学生 enrollment 历史展示高等教育课程之间的相似性。此外,教育研究越来越多地建立在神经科学、认知科学的基础上,可以想象学习科学将从化学或生物学角度研究大脑的进步中受益。例如,先进的人工智能技术可能有助于更好地理解学习和教育表现的临床和社会遗传维度(Isungset et al., 2022[17]; Morris et al., 2022[18])。
化学和生物学是生成式人工智能应用领先学科,这主要得益于大量数据的可用性和运作机制的本质上是组合性的。大多数模型的任务是将某种性质(治疗性或物理性)与化合物的组成联系起来。因此,模型可以预测给定化合物的性质,或者相反,预测具有给定性质的化合物的组成。一些模型还可以进行逆合成分析,即预测允许用给定成分(反应物)生产特定化合物的化学反应序列或网络。
这些性质和反应服从已知的物理和生物学规律,但由于组分的数量、许多机制的线性以及聚合性质对微小修饰的敏感性,在大多数情况下难以分析解决,甚至不可能。对于生物学来说,化合物极其复杂(蛋白质可以由数千个分子组成)。大多数模型将数据分析与领域的基本规则知识混合,使生成的项目符合领域已知规律。
化学或生物学与语言之间存在很强的类比:两者都是组合性的——由基本组分(单词或分子)组成,这些组分组合产生 emergent 特性(意义或物理特性)。因此,用于训练大型语言模型的技术已直接转移到这些领域。某些研究人员甚至直接使用大型语言模型进行化学分析,尽管大型语言模型在该领域的训练基础不如专用模型。他们指出:”我们的结果表明,大型语言模型可以准确地从局部和全局角度推理化学实体,分析单个反应以及整个合成路线,并且这种能力可以通过搜索算法加以利用,以更灵活的方式解决化学问题。”(Bran, 2025[19])
一些模型由处理不同数据类型并利用这些数据类型之间协同作用的多个互连模块组成。某些模型将自然语言与化学或生物数据关联起来,允许用户用自然语言解释查询关于某种特定性质将具有的化学组成。
专栏13.1提供了专业科学人工智能模型的示例。
专栏13.1 专业模型的示例
ESM3是一个通过语言建模生成蛋白质三个基本特性——序列、结构和功能——的生成式模型。ESM3可以从每种输入类型的指令中接受提示。这允许从原子级结构到描述功能和折叠拓扑的高级关键词,在多个抽象级别上指定提示(Hayes, 2025[20])。
AlphaFold是Google DeepMind生成的一系列模型,旨在预测蛋白质的三维结构,其主要作者因此获得了2024年诺贝尔化学奖。
AlphaFold对结构生物学产生了广泛而深刻的影响(Saplakoglu, 2024[21])。所有使用蛋白质的研究人员现在都使用AlphaFold2或替代方案,使他们能够将时间和精力重新定向到其他任务。由于”简单蛋白质”问题已经解决,研究人员正在转向新问题:复杂蛋白质(例如形状依赖于上下文或复合型的蛋白质)和核糖核酸,引发了AlphaFold3和其他模型。AlphaFold对下游研究的影响(因为蛋白质的形状被用作其他研究的输入)是巨大的:重振基于结构的药物发现;在生物学中加速假设创建;为理解细胞内发生的复杂相互作用开辟新途径。
AlphaFold仍然可能给研究人员带来风险。错误发生在复杂情况下,如果不加检查,有时会导致错误的假设。
DeepMind的AlphaProof和AlphaGeometry 2(2024[22])解决了六道国际数学奥林匹克问题中的四道,达到银牌得主水平。这些系统将形式语言训练与神经符号推理相结合,减少”幻觉”并实现严格验证(Castelvecchi, 2024[23])。进展令人印象深刻,但仍不足以应对研究级数学。
Krenn等人(2025[24])开发了Urania,这是一种用于设计引力波探测器的人工智能算法。该系统产生了大量创新设计,其中一些将灵敏度提高了十倍以上;此类设计重新构想了已知技术,为天体物理学开辟了新可能性。
大型语言模型可用于模拟实证研究中的人类参与者,例如生成合成访谈、参与者之间的互动或在特定情况下的特定行为。关于模拟人类行为的研究非常活跃,模型特别在心理学材料上进行训练(例如Binz, 2025[25])并整合认知科学知识。在人类行为数据上训练的人工智能模型可以作为测试平台,模拟包括教育环境在内的各种背景下的人类决策。它们可能发挥类似于类器官(自我组装的结构,模拟体内器官的某些特性)在医学研究中的作用。此类模型加速研究并降低成本。
然而,这种方法的潜力仍然存在局限性,因为在复杂情况下,大型语言模型模拟人类行为多样性的能力仍然有限。例如,在一项关于工厂工作条件的研究中,现场工人和管理人员对与工作和工作场所相关的各种方面可能有不同的反应。然而,大型语言模型参与者生成的回应可能会将这两种观点合并为一个答案,混淆了不符合现实的 attitudes(Kapania et al., 2025[26])。
如果人工智能的这种应用是有成效的,它可能对教育研究产生重大影响,特别是对于生成调查答案,根据调查实施者的说法,收集这些答案已变得越来越困难。例如,在标准化评估的制作中,(Liu, 2025[27])表明,多代理人工智能模型汇集了大型语言模型集合,可以作为”合成受访者”,产生与大学生心理测量特性密切相关的回应分布。Pardos和Borchers(2026[16])认为,基于大型语言模型的校准可以补充有限的学生回应数据,降低成本并加速项目验证周期。虽然人类回应仍然是必不可少的(特别是因为它们用于生成模拟回应),但人工智能生成的回应可以对它们进行增强,并且与测试项目的答案一样,在保持一致性的同时扩大其方差。虽然需要时间来评估模拟答案何时能在不扭曲人类回应的情况下增加价值,但如果成功的话,这是人工智能影响的一条特别有用的教育研究途径。
管理科学知识
“我们是站在巨人肩膀上的矮人,”沙特尔的热尔纳姆(Bernard de Chartres) famously 说,描绘了知识的积累动态:新发现主要是过去发现的阐述和组合。获取和掌握现有知识对于研究人员在此基础上进行新发现至关重要。假设生成是研究过程和新发现的关键;它与所依赖的现有知识密切相关,但也涉及将在下一节考察的独特机制。
随着科学出版物(文章、数据库、图像、计算机程序等)数量的不断增加,研究人员越来越难以跟上自己领域的进展,尽管学科内的专业化程度不断提高。因此,研究人员面临新的挑战:改进自己缺乏熟悉的知识。人工智能催生了支持研究人员完成这些任务的工具,如通用大型语言模型或专用模型(如Elicit、Consensus、Clarivate、PaperQA2、BioloGPT)(You, 2024[28])。这些工具可以执行知识管理操作,如文献检索、摘要和文献综述,我们将在下面考察。这些模型在教育研究中同样适用,尽管它们没有针对该领域进行微调。
研究人员将特定研究问题输入模型(例如,”病毒X是否导致疾病Y?”),模型返回一个与查询相关的出版物列表,并对每个出版物给出与其结果相关的摘要。一些模型提供文献的综合(共识)视图,列出同意或不同意该共识的出版物及相应论点。一些工具可以生成相关研究领域的图示,基于引用关系展示出版物之间的联系(谁引用了谁,谁与谁共同被引用等)(Kudiabor, 2024[29])。
与大型语言模型相比,专用模型旨在提供更高的可靠性,因为它们仅使用科学出版物,避免博客和其他声誉较低的资源。某些工具还可以提供除上述搜索结果之外的其他产品,如知识图谱(提取领域的主要概念或结果,并在知识图谱中将它们相互关联)。某些平台具有”与PDF对话”功能,允许用户上传论文并就其内容提出问题(Heidt, 2025[7])。
人工智能模型可以根据请求生成出版物的摘要,使研究人员能够快速概览一组感兴趣的论文,节省阅读时间并允许专注于最相关的论文。然而,此类摘要的质量有时可能较低。Peters和Chin-Yee(2025[30])比较了人工智能摘要与一些期刊为医学和科学领域4900个示例提供的人工摘要。他们发现,所有人工智能模型往往过度泛化论文中呈现的结果,因为它们经常省略限制结果有效性的重要细节,并遗漏相关 nuances。例如,它们可能只是声明某种药物对治疗某种疾病有效,而不具体说明在哪种剂量或哪组患者中。这反映了人工智能模型难以完全识别智能人类读者认为重要的”细节”的重要性。同样问题也适用于教育——结果可能因国家、社会经济背景、性别等因素或多或少地 relevant。
生成式人工智能模型可以提供与特定问题相关文献的结构化摘要(Skarlinski et al., 2024[31])。这些综述对研究人员很有用,可以帮助他们广泛了解问题,同时节省时间并确保不错过最重要的相关出版物。
一些模型提供”系统”综述,以标准化方式包含每篇论文方法和结果的 granular 信息;如果研究人员希望重现实验或进行元分析,这是必要的。一些研究人员对人工智能生成系统综述的质量持怀疑态度(Pearson, 2024[32]),因为人工智能模型往往跳过像药物精确剂量这样的具体但重要的信息,如上所述。对于项目式学习或讲授的影响或教育技术使用等研究的具体教学背景,情况也是一样的。
更一般来说,用人工智能进行的文献综述存在某些局限性。首先,许多模型只能访问所有出版物的摘要和开放获取出版物的全文。获取大部分科学文献的途径受到限制(尽管出版商的工具当然可以访问他们自己的出版物),因此人工智能生成的综述中经常遗漏许多重要的研究发现,特别是方法。
其次,生成式人工智能文献综述工具有时难以识别领域中最相关的论文,难以区分最新文献与过时文献,可能首先列出曾经主导一个领域但现在已经过时的文献。
此类系统仍可用于更新人类撰写的文献综述,而不是生成新的文献综述。人类不太可能经常更新综述,人工智能可以为此提供支持,即使权威综述可能仍需要人类参与。
最新的模型,如OpenAI Deep Research或Gemini Deep Research,可以提供”研究报告”,它们超越文献综述,提供更广泛的背景和上下文并识别待解决的问题(Heidt, 2025[7])。用户可以输入查询以及自己的数据(文章等),模型返回完整报告,包括文本、图表和相应的书目参考文献。这些模型模仿人类处理研究问题的方式。当探索用户不熟悉的领域时,这尤其有趣:它有助于以清晰的语言获取通用知识(Jones, 2025[33])。
一个专用模型PaperQA2,撰写维基百科风格的科学主题摘要,有引用且比现有的人类撰写的维基百科文章准确得多。它可以识别科学文献中的矛盾,这是对人类的挑战性任务(Skarlinsky et al., 2024[31])。
某些模型生成的研究报告草稿中会识别知识差距,接近于提出进一步可能的研究主题。这些报告的质量存在争议(Jones, 2025[33]):它们通常包含不正确(或捏造)的引用,难以区分权威信息与简单假设,不能准确传达不确定性。
假设生成是研究人员的定义性活动。它包括从文献或数据中生成全新的、似真的和可检验的想法。文献综述关乎已知的东西,而假设生成关乎进入未知:识别文献未回答的问题的可能响应,同时与已建立的知识保持一致。直到最近,这一直是人类的保留地。现在人工智能也可以做到这一点。它通常涉及三个步骤:假设生成、评估/验证(或拒绝)和改进/完善。
在教育研究中,这些技术可以帮助解释学习轨迹或教育结果中某些令人困惑的方面。人工智能技术可以结合多个远程信息源来生成原创假设。例如,可以想象人工智能系统基于国际或国家数据集生成假设,利用这些数据集的大规模性对解释学生成绩增减的因素提出假设。但它也可以将这些结果与其他可能的来源联系起来,为教育研究人员指出在其数据来源中不易立即察觉的可能解释(例如,学生成绩可能因最近社会服务的可用性而提高,这些服务导致学生旷课减少或心理健康改善,因为他们的父母得到了更好的支持)。
大多数模型从文献中提取假设,但有些模型也可以直接从提供给它们分析的数据中提取。与人类相比,人工智能模型的优势在于对文献的更广泛了解:不仅在相关学科中,而且在其他学科中,访问更多样化的来源(假设模型已经训练或可以访问这些知识,这可能存在问题,如自动文献综述的局限性所说明的)。然而,人工智能模型在自动从文献中提取假设时面临特定困难:1)源文本可能没有明确说明问题和相应的假设是什么;2)文献中陈述的问题与假设之间的联系可能并不直接;3)假设的新颖性或可行性可能难以评估,但需要测量和排序;4)最初设计的假设通常需要改进以加强其新颖性或可行性,需要在从文献提取后进行进一步操作。
研究人员与模型交互的一种简单方式是通过头脑风暴,提示如”给我十个可以解释A如何影响B的机制想法”。研究人员也可以挑战模型,提交自己的假设并询问大型语言模型的反论点或替代假设。这个简单的程序允许初步建议,但要制定结构化和似真的假设,需要更清晰的 approach,使用专用模型。
一种方法是将高度结构化的数据插入提示中,以严格约束模型的响应。例如,研究微塑料如何通过土壤运输并进入地下水的科研人员可以使用可视化工具Research Rabbit。该工具采用单一的”种子论文”并生成由主题、作者、方法论或其他关键特征链接的互连研究网络。通过将其结果插入大型语言模型,”查询作品中的隐藏联系或新想法”是可能的(Heidt, 2025[7])。
关于大型语言模型从语料库阅读时难以将问题和假设联系起来的问题,一个解决方案是微调现有的大型语言模型,以便更好地识别论文中的问题和假设。O’Neil等人(2025[34])汇编了一个5500个科学假设的数据库(HypoGen),他们用它来训练现有的大型语言模型。这些数据的结构方式使问题、假设以及从问题到假设的推理链变得清晰。
使用人工智能模型从数据中提取假设因人工智能缺乏可解释性而变得困难。例如,某些事件之间的相关性可能难以归因于这些事件的特定特征。模型会观察到现象A与B相关,但它无法说出这是由于这些现象的特征C还是D。模型可以看到人类看不到的数据模式,但模型难以用语言表达它们作为可以被人类理解并检验的假设。Ludwig和Mullainathan(2023[35])提出了一个程序,使人工智能在数据中发现的相关性能够用语言表达,以便可以向人类解释并检验。为此,他们使用反事实:生成夸大初始数据中发现的相关性的合成数据,直到相关模式对人类可见并可以解释。
从文献中推断假设可能不够充分或完全令人满意,因为”原始”假设可能缺乏足够的新颖性或清晰度,与来源过于相似,plausibility弱(与证据不完全一致),或者难以进行实验检验。因此,对从文献中提取的想法进行完善过程是有必要的。这是人工智能在科学领域面临的最困难挑战之一,因为它需要想象力和推理能力:在保持核心的同时改进想法的能力;逻辑推理的能力;评估想法与”现实世界”接近程度的能力等。该领域正在发生许多进展。主要技术包括:多步推理(”思维链”,要求机器明确其在推理中遵循的步骤);强化学习(训练模型以加强其成功特征并削弱其他特征);进化计算和多代理系统(见下文)。自2024年以来开发的模型包括一种或多种这些技术。
进化计算是一种受达尔文进化中突变和自然选择启发的技术。它从文献综述开始,从中提取初始假设列表。它对算法进行小的随机更改,并选择能提高模型效率的算法。为此,模型通过运行算法并测量其性能来进行自己的”实验”。之后,模型生成并评估论文。在这样”扩充文献”之后,算法可以再次开始循环,现在基于自己的结果(Castelvecchi, 2024[23])。
代理式人工智能也正在应用于科学。代理是一个自主系统,可以引导各种工具朝着给定目标。多代理系统由多个具有特定目标和专业技能的代理组成;每个代理引导一个人工智能模型(如大型语言模型)并与他人密切互动,在”主导代理”的监督下,就像管弦乐队的指挥一样。一些模型还集成了推理能力,如上述”思维链”。多代理模型旨在像一组研究人员一样运作。一些研究人员专注于特定学科;一些研究人员扮演特定角色,提出建议或挑战他人的建议或将它们结合起来;在每一步,他们被分配特定任务,并使用各自的工具实施;他们开会并 confrontation 各自的发现,公开讨论,其结论包含在与人类研究人员共享的报告中。整个过程从一个提示开始,包括问题描述和上下文信息,提交给模型。主导代理和代理然后设计研究计划,可能包括一系列子问题、一组并行任务、代理所需技能列表等。然后可以进行迭代过程,其中每个代理完成其负责的任务,并向主导代理和其他代理报告;主导代理在每个阶段综合发现并监控整个过程的进展。最后,模型可以起草研究报告(Biever, 2025[36])。
在教育领域,具有生成式人工智能代理的多代理模型例如用于开发评估项目。它们可能对教育研究很有希望,教育研究通常是跨学科或处理广泛的社会技术问题(如人工智能在教育中的采用和使用)。教育研究人员可以使用此类模型来确保汇集不同类型的专业知识、信息来源和约束,例如在儿童学校节奏方面产生新想法,这涉及儿童生物和心理发育及需求、学习科学和教学法、父母工作时间表等方面的专业知识(图13.4)。还可以想象一些有成效的用途来为教育政策研究产生想法或改进通常假设,其中一些人工智能代理扮演不同教育利益相关者的角色,就解决某些教育政策问题(如提供平等机会)提供想法。然后,多代理模型可以在这个模拟环境中提出教育干预或政策的新建议。
图13.4 一种可能的跨学科人类–人工智能协作教育研究模型
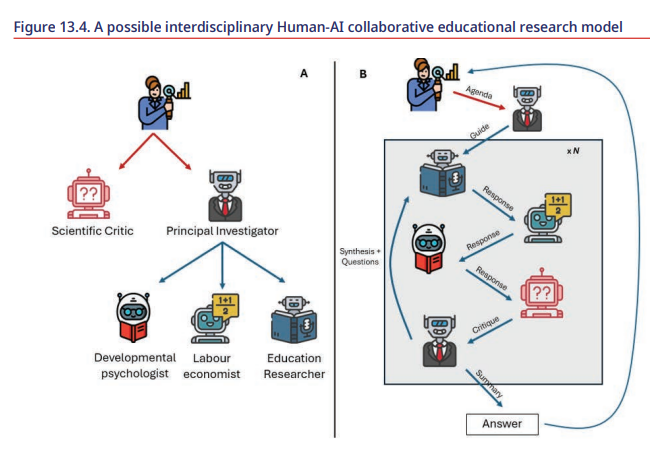
注:这个想象中的案例将专栏13.2的想法应用于教育研究。在面板A中,人类研究人员提供了一个简要说明,例如关于学生的学校节奏,并要求一个生成式人工智能代理(首席研究员)建立一个跨学科研究团队,以及一个评论家来 review 跨学科团队的产出。在这种情况下,人工智能代理选择其他人工智能科学家的专业知识(发育心理学、教育研究、劳动经济学)。他们可能生成研究文献综述,检索旧文献并生成新假设。面板B说明了人类研究人员如何通过迭代要求人工智能代理集体讨论具体问题取得进展:一旦人类设置了会议的议程,如在虚拟实验室中,生成式人工智能科学代理分享他们的专业知识,由评论家进行评论,允许在向人类研究人员提供答案之前进行迭代改进——然后他可以提出后续研究问题。
来源:作者 elaborations。
Box 13.2 presents some examples of (specialised) scientific multi-GenAI agent models.
专栏13.2 基于生成式人工智能的多代理模型示例
当用自然语言提供研究目标时,系统搜索并分析相关文献,综合和整合现有工作,生成新的研究假设和用于后续验证的实验协议。联合科学家通过引用关键来源并解释其建议背后的逻辑来支持其建议(Gottweis, 2025[37])。
给定背景问题描述,模型首先从过去文献中动态检索灵感,形式为相关问题及其解决方案,以及来自科学知识图的上下文。这些检索到的灵感用于将生成的想法扎根于现有文献。此阶段生成的想法不一定是新的。模型有能力迭代提高其生成想法的新颖性。给定由大型语言模型生成的想法,比较该想法与文献中现有研究的相似程度;如果发现强烈重叠的研究,模型的任务是更新其想法以相对于先前工作更具新颖性(很像一位优秀研究人员会做的那样)。该模型还引入了一个情境对比模型,鼓励相对于背景上下文的新颖性(Wang et al., 2024[38])。
Swanson等人(2025[39])开发了虚拟实验室,这是一个多代理模型,在人类研究人员的监督下,指派不同的人工智能代理完成不同任务,以执行跨学科科学并研究广泛而复杂的研究问题。首先,人类研究人员定义两个核心人工智能代理:首席研究员(PI)和科学评论家。基于简短的项目描述,首席研究员创建额外的人工智能科学家代理,分配它们特定的专业知识、目标和角色。人类-人工智能协作然后通过两种类型的工作流程发生:团队会议和”双边”会议。作者描述团队会议如下:首先,人类研究人员设定会议议程,然后首席研究员提出初步想法和指导性问题,之后每位科学家代理轮流贡献。科学评论家 review他们的输入,首席研究员综合讨论,提出后续问题。经过几轮讨论后,首席研究员为人类研究人员生成最终总结和结论。在”双边”会议的情况下,指定的人工智能科学家代理回应人类研究人员设定的议程,接受科学评论家的评论,并迭代改进其答案。经过多轮后,人工智能科学家交付精炼的最终回应。
DeepMind的AlphaEvolve
AlphaEvolve基于(Google)大型语言模型。每个任务从用户提供一个问题、评估标准和初始解决方案开始。然后大型语言模型生成数百甚至数千个可能的变体。评估算法根据定义的指标对这些替代方案进行评分,表现最好的引导大型语言模型提出新想法。通过这个迭代过程,系统逐渐开发出越来越有效的算法 population(Gibney, 2025[13])。
生成式人工智能模型在生成、完善和评估科学假设方面效果如何?证据仍然很少,因为测试此类模型既复杂又昂贵。最有效的测试是通过执行实际研究并检查模型的成就来实施的。诊断结果多种多样,这是由于模型的多样性、研究问题的多样性和测试方法的多样性。
在广泛的研究问题上,这些模型似乎能够提供有用的建议,指向可能有成果的研究方向。这得益于它们对文献的良好获取以及以高度结构化方式处理文献的能力。根据Anthropic(2025[40]),”我们的内部评估表明,多代理研究系统特别擅长于 breadth-first 查询,这些查询涉及同时 pursuing多个独立方向。”
当涉及更具体的研究问题时,证据参差不齐。有一些令人印象深刻的成就,模型能够识别和描述后来被研究人员成功检验的假设(见专栏13.3),但也有不太成功案例。成功案例伴随着人类在过程中的 significant 参与。
某些研究还指出,某些模型倾向于提出似是而非但并非真正新颖的解决方案,包括一些已经在过去探索过并被放弃的方案。Wang等人(2024[38])使用具有领域专业知识的人类标注器进行了广泛的评估实验,以评估一个名为Scimon的多代理模型的提议。他们发现”想法在新颖性、深度和有用性方面仍然远远落后于科学论文——这对构建生成科学想法的模型提出了根本性挑战。”
关于人工智能联合科学家(专栏13.2),专门研究机器学习:”作者承认人工智能科学家产生的论文只包含增量开发。一些其他人在社交媒体上的评论很尖锐。’作为期刊编辑,我可能会 desk-reject 它们。作为审稿人,我会拒绝它们。’一位在在线论坛Hacker News上的评论者说。”(Castelvecchi, 2024[23])
在数学方面,也有矛盾的证据。某些测试指出,某些模型在国际数学奥林匹克银牌或金牌水平问题上声称取得的成就 due to “数据泄漏”(奥林匹克是数学领域的全球竞赛):解决方案之前已发布并被模型访问(Petrov et al., 2025[41])。另一方面,专业数学家的严格测试表明,OpenAI推理模型o4.mini可以解决他们提交的大多数博士级问题,展示了极其强大的推理能力。然而,共识是 current 模型尚未达到数学研究的水平,尽管它们正在接近(Chiou, 2025[42])。
还需要提及两个 further caveats。首先,并非所有测试的负面结果都会被发表,模型的局限性可能被低估;其次,很难估计模型工作中的人类参与程度,但有时可能很重要,然后模型的作用可能被高估。然而,这些模型仍处于开发的非常早期阶段,在不久的将来会有很大进展。
专栏13.3 生成式人工智能发现的案例
人工智能联合科学家在一个花了数年才解决的问题上进行了测试:cf-PICIs(一种针对噬菌体的防御机制)如何在细菌物种间传播。它生成并检验了几个假设。其排名最高的假设与实验确认的机制相匹配。其他假设开辟了新的研究途径,展示了人工智能作为科学发现 creative engine 的潜力。生成的假设是新颖的、逻辑连贯的和可实验检验的,突出了系统加速发现和建立跨学科桥梁的能力(Penadés et al., 2025[43])。
虚拟实验室处理针对新SARS-CoV-2变体的纳米抗体结合设计。它结合了几个模型——ESM、AlphaFold-Multimer和Rosetta25——来突变靶向刺突蛋白的纳米抗体。在92个设计的纳米抗体中,超过90%被表达和可溶,其中两个显示出对最近变体JN.1和KP.3的独特结合。这展示了人工智能-人类协作提供复杂、验证科学结果的潜力(Swanson et al., 2025[39])。
AstroAgents:用于追踪外星生命的人工智能
AstroAgents是一个多代理系统,有八个人工智能代理在天体生物学中生成假设。使用大型语言模型(Claude Sonnet 3.5、Gemini 2.0 Flash),它分析了陨石和土壤质谱数据,从Gemini产生了101个假设,从Claude产生了48个。Gemini的想法更新颖但容易出错;Claude的更清晰但不太原创。总体而言,该系统产生了超出人类能力的似真的、模式发现的见解,可用于分析计划从火星返回的样品等样品(Biever, 2025[36])。
专栏13.4 人工智能研究助手的示例
该系统自主识别新的研究问题,提出方法并设计实验,通过基于大型语言模型的审阅代理反馈进行完善。从一篇核心科学论文开始,ResearchAgent通过学术图链接相关出版物,并在从许多论文构建的知识库中提取的概念扩展其范围。模仿同行评审,它使用多个大型语言模型审阅代理,提供评论和迭代修订。这些代理与人类偏好一致,其评估标准源自通过大型语言模型提示的真实人类判断。
该系统围绕专门化的代理构建,这些代理在研究的不同阶段进行协作。在实验阶段,博士和博士后代理设计研究计划,而机器学习和软件工程师代理处理数据准备和编码任务。然后自动化模块生成、测试和迭代改进机器学习代码。它还包括一个大型语言模型驱动的修复功能,用于在执行过程中纠正错误。在报告撰写阶段,教授和博士代理将结果编译成结构化报告。这个过程模仿同行评审,有迭代修订和检查点,可以是自主的或由人类指导的。
来源:Baek et al. (2025[46]), ResearchAgent: Iterative Research Idea Generation over Scientific Literature with Large Language Models.
自动化科学:研究助手与机器人实验室
上述人工智能系统仅限于研究的认知任务:分析和生成信息。其他系统更进一步,旨在执行研究助手的全部任务,特别是实验设计(研究助手),甚至实验的实现(机器人科学家)。
自2024年以来,人工智能研究助手的供应激增(见专栏13.4)。它们可以与(Baker, 2026[44])描述的教学助手进行比较,尽管它们的功能和工作方式不同。人工智能研究助手的共同特征如下:1)它们执行研究助手期望的所有任务:文献综述、假设生成、实验设计、起草文章;2)它们在技术上类似于上述假设生成模型(多代理等);3)它们非常互动,因为它们的功能涉及与监督人类的频繁和重要的交流,人类仍然密切控制研究过程;它们毕竟只是”助手”。
根据So(2025[45]),人工智能研究助手提供众多好处,包括加速研究时间表、全天候可用、个性化支持、增强客观性以及改善非英语母语者的可访问性。人工智能研究助手正在发展为支持各种协作模式,从被动助手到完整研究合作伙伴。尽管能力令人印象深刻,人工智能研究助手面临重大挑战,包括生成不准确信息、批判性分析的局限性以及围绕抄袭和归属的伦理问题。
“机器人科学家”标志着研究循环最后一步——实验执行——的自动化。机器人科学家通过将实验室设备连接到人工智能系统来工作:人工智能设计实验并控制设备使其执行这些实验。
为什么要自动化实验?这里有一个例子。根据先驱者Ross King(2024[47])的说法:
研究真核系统生物学是一项复杂的任务,因为即使像酵母这样的简单真核细胞也有数千个基因、蛋白质和其他小分子,它们以复杂的空间和时间方式相互作用。模型的高复杂性意味着它们的开发和评估需要根据假设执行数百万次实验。只有具有自动化实验室的人工智能系统才有能力 plan、conduct 和监控如此大量的实验。
在这种情况下,机器人 allow 研究人员执行超出人类能力的实验。机器人实验室的额外优势是,它们的实验产生大量高质量的 controlled data,可用于训练人工智能模型。
化学方面的一个例子是CRESt(Ren et al., 2023[48]):用户像与同事一样用自然语言与CRESt交流。CRESt帮助制作和运行实验,检索和分析数据,打开和关闭设备,为机器人手臂供电,记录发现,并在出现需要他们注意的事情时提醒科学家。CRESt辅助的研究人员识别出了燃料电池的候选合金。
虽然对许多科学领域都很重要,但实验室工作的自动化似乎与教育研究不太相关,因为大多数实验涉及控制或真实环境中的人类。然而,这一技术可以支持化学、生物学或神经科学领域的相关研究,而这些领域的成果能够助力学界理解人类学习机制、探寻学习障碍的成因,为教育研究提供底层科学支撑。
综合
表13.1总结了生成式人工智能在研究过程不同步骤的应用价值、当前技术成就与现存核心局限性,系统梳理了AI赋能科研全流程的能力边界。
表13.1 研究过程的阶段与可用人工智能工具的能力
| 研究任务 | 生成式人工智能成就 | 生成式人工智能局限性 |
| 识别研究问题 | 识别数据中的异常;挖掘学术文献中的研究空白 | 提出的研究提案有时过于浅显、显而易见,或存在内容过时、已有成熟研究成果的问题 |
| 文献综述 | 多款人工智能模型可高效完成文献综述工作,能够实现对研究领域较为全面、准确的整体梳理 | 存在内容幻觉问题,可编造不存在的文献来源;难以精准区分前沿可靠研究成果与过时、存疑的研究内容 |
| 制定和完善研究假设 | 依托多元技术路径赋能假设研发,可与研究人员头脑风暴、模拟学术研讨,也可通过多代理推理模型辅助构思、检验研究想法 | 生成假设的原创性与实践可行性整体有限,仅在最新模型应用中逐步改善 |
| 整理、分析和生成数据 | 基础生成式模型可完成高复杂度的数据分析与数据生成工作,适配多领域科研数据处理需求 | 模型专业化属性强,需依托海量数据完成训练,且分析生成的结果可解释性较差 |
| 设计和实施实验 | 新型AI模型具备完整实验设计能力,搭配人工智能驱动的机器人实验室可落地实验执行工作 | 技术整体处于早期落地阶段,成熟度与稳定性不足 |
| 推断研究结论和起草论文 | 可基于实验与分析结果推导研究结论,关联现有学术文献,并完成论文初稿撰写工作 | 虽有部分成功应用案例,但生成论文的内容质量、研究新颖性与结论可靠性仍存在明显短板 |
© OECD 2026 OECD《数字教育展望2026》 233
生成式人工智能在科学研究中的影响与挑战
生成式人工智能技术能力持续迭代,在科研领域的应用渗透率不断提升,深刻重塑科学研究的核心范式,对科研创造性、研究真实性与可靠性、学术出版规范、产学研合作模式等科学事业核心维度产生全方位影响,同时也带来诸多全新挑战。
在科学研究领域,创造性的核心内涵是产出新颖且具备学术价值、实践价值的研究成果。实证研究数据与科研人员实践经验表明,生成式人工智能可通过独立产出研究发现、赋能科研人员创新思维两种方式,直接或间接影响科学创新,同时也对学术界集体创造性产生深远作用。
科学研究的创造性,核心依托科研人员掌握现有知识、并突破现有认知边界的高阶思维能力(Simon, 2001[49])。当前主流生成式人工智能模型擅长存储、整合海量学术信息,依托统计算法挖掘数据潜在规律,对现有研究思路、学术观点进行合理重组与优化,实现渐进式创新。但多数研究证实,AI模型难以脱离训练数据范畴,无法自主推导、生成全新的概念与理论,缺乏真正的原创性思维。
同时,AI的科学推理能力存在明显短板,难以完成严谨的逻辑推演,而逻辑推理是提炼科学观点、开展创新研究的核心基础,这也进一步限制了其突破性创新能力。业内普遍认为,当前大型语言模型仅能实现表层学术观点的组合优化,无法产出真正新颖、具备落地价值的前沿科研方向,难以支撑颠覆性科学突破的诞生,仅能在人类深度参与的前提下完成渐进式创新(Shojaee et al., 2025[50])。
不过,生成式人工智能也涌现出诸多突破性创新案例,展现出独特的科研创造潜力。例如ESM3模型设计的荧光蛋白变体,与自然界现有蛋白结构差异显著,这类自然演化需要数亿年才能形成的成果,可通过AI快速生成(Hayes, 2025[20]);在自然语言处理研究实验中,Claude 3.5 Sonnet生成的研究问题创新性超越人类专家,仅在实践可行性上存在不足(Chenglei Si, 2024[51]);人工智能算法可重构引力波探测器设计方案,部分创新设计可将仪器灵敏度提升十倍以上,为天体物理学研究开辟全新路径(Krenn, Drori and Adhikari, 2025[24])。但此类创造性成果数量有限,且高度依赖特定领域场景,不具备普适性。
AI具备科研创新潜力的核心优势,在于其可覆盖广阔的解决方案搜索空间,能够批量筛选、组合海量研究思路,探索人类科研视野之外的潜在方案。科学发现往往依托偶然性探索,而AI可高效测试、组合海量创新思路,挖掘人类难以触及的研究方向,这一优势在化学、材料科学、生物学等注重组合创新的领域尤为突出。即便仅对现有研究体系进行深度整合优化,也能产出具备显著价值的创新成果。
除此之外,AI科研创造性的发展仍存在多重局限:人类创新由好奇心驱动,具备主动质疑、深度探索的特质,而当前AI的人工好奇心仍处于研发初期,无法自主发起深度探究;AI可高效识别大数据中的表层异常现象,但难以挖掘复杂理论体系中的深层逻辑矛盾,无法支撑高阶科研突破;同时,AI普遍存在的“幻觉”问题,会生成看似合理、实则错误的观点与文献,这类虚假输出不具备实际学术价值,并非真正的科研创新。
人类–人工智能协作创造性(“增强创造性“)
现阶段生成式人工智能的独立创新能力仍无法比肩人类科研创造性,但二者具备极强的互补性,合理的人机分工协作模式,能够构建混合创新体系,显著提升科研创新效率与质量。当前科研领域已形成多种成熟的人机协作创新模式。
在头脑风暴环节,AI可打破人类固有思维定式,挑战传统研究假设,激发全新科研思路,相关实验证实,依托大语言模型辅助创作与研究的人员,产出成果的创造性显著高于独立工作者(Anderson、Shah和Kreminski, 2024[52])。在科研效率层面,AI可承接文献整理、文本润色、数据预处理等重复性基础任务,解放科研人员时间精力,使其专注于高阶创新思考与核心科研工作。
同时,人机协作可实现科研探索与落地应用的动态平衡:AI擅长整合、优化现有成熟研究成果,实现技术落地与迭代升级,人类科研人员则可专注于前沿未知领域的突破性探索(Gans, 2025[53])。依托进化计算技术,AI可快速扫描海量研究组合空间,筛选高潜力研究方向,为人类决策提供精准参考,但研究思路的可行性、学术价值仍需人类专业判断(Si et al., 2024[54])。此外,新型AI科研助手支持自主、辅助双模式协作,科研人员可自主把控干预节奏,灵活引导AI开展科研工作,适配不同研究场景需求(Schmidgall et al., 2025[55])。
整体而言,当前生成式人工智能的核心价值是**赋能、补充人类创新**,而非替代人类科研创造性。但学界也存在潜在担忧:长期依赖AI完成基础思考与文本创作,可能弱化人类批判性思维与独立思考能力。相关研究表明,AI的便捷性会降低科研人员深度思考的主观投入,容易引发技术依赖,削弱独立解决科研问题的能力(Lee et al., 2025[56])。不过这类结论均基于实验室单次任务实验,尚未在真实、长期的科研场景中得到验证,仍需进一步研究佐证。
从宏观科研生态来看,AI的普及虽然提升了个体科研人员的产出效率,但可能削弱学术界整体的集体创造性,引发科研同质化问题。大规模实证研究显示,使用AI工具的科研人员论文产出数量、引用量更高,但研究选题高度趋同,集体探索的研究领域不断收窄,AI更多赋能成熟、数据丰富的研究领域,难以推动跨领域、突破性的全新探索,导致科研生态多样性下降(Evans et al., 2024[3])。
这一同质化问题在创意研究领域同样显著:AI辅助创作可提升普通研究者成果的创新性与完整性,但会导致不同研究者的产出风格、思路趋于统一,差异化创新减少(Doshi和Hauser, 2024[57])。对比实验显示,相较于传统协作工具,依托ChatGPT开展研究的科研人员,产出思路的语义差异性更低,且研究者对自身研究成果的主观责任感明显弱化(Anderson, 2024[52])。
综上,在可预见的未来,生成式人工智能无法取代人类在科学创新中的核心地位,颠覆性科研突破仍需依托人类智慧完成。但AI能够全方位赋能人类科研创新,通过拓展研究组合维度、简化重复性任务、提升偶然发现概率,重塑科研创新模式。与此同时,过度技术依赖、科研生态同质化、人类批判性思维弱化等风险,将成为未来科研创新体系需要重点规避的问题。
真实性与可重复性是科学研究的核心支柱,所有科学结论均需经过规范化验证、可重复检验,才能被学术界认可。生成式人工智能的技术特性,使其在科研真实性、可靠性层面存在天然短板,频繁产出不准确、不严谨的研究结果,对科研公信力形成挑战。
AI科研失真的核心技术短板,在于其对“真实”的认知仅局限于训练数据集范畴,远小于复杂多变的现实世界。尤其主流文本类大语言模型的训练数据本身存在真伪混杂、观点偏差等问题,导致模型无法精准判别现实世界的科学规律与事实边界。
最突出的问题即为“幻觉捏造”,模型会随机合并、混淆不同训练数据的碎片化信息,生成看似合理、逻辑通顺但完全错误、无依据的结论,最常见的表现是编造不存在的文献引用、错误关联作者与研究成果、虚构实验数据与结论。这一问题源于两大技术缺陷:一是数据压缩机制,模型在数据解压过程中易混淆相似信息,造成内容错乱;二是缺乏人类特有的元认知能力,无法在输出结论前完成自我校验、逻辑复盘,叠加多数大模型的谄媚偏差,会为了适配用户查询强行输出低质量、低可信度内容,进一步加剧失真问题。
可重复性是科学研究规范化的核心标准,要求研究方法、数据、流程完全透明,可被其他研究者复刻验证。当前生成式人工智能模型严重违背这一科研准则,引发新型可重复性危机。主流商用AI模型均为黑箱模式,神经网络参数、完整训练数据未对外公开,无法精准拆分模型、数据、算法对研究结果的影响,科研成果溯源困难。同时,AI模型内置随机运算机制,相同提示词可能产出差异化结果,且模型持续迭代更新,新旧版本参数差异会导致同类研究输出不同结论,进一步降低研究可重复性。此外,部分模型依托企业私有涉密数据训练,数据壁垒进一步加剧了科研不透明性(Callaway, 2025[15])。
开源模型的发展为破解这一困境提供了路径,Llama等开源权重模型、公开数据集与算法框架,有效保障了科研透明度。AlphaFold2的普及应用充分证实,开源开放的技术体系能够推动科研成果持续迭代、集体优化,是科学研究累积进步的核心基础(Saplakoglu, 2024[21])。
与此同时,AI也为提升科研可重复性、透明度提供了全新机遇。AI可完整记录科研全流程的操作细节、数据变化、迭代过程,实现科研行为全溯源,相较于人类记录更加精准、全面,极大提升研究过程的可追溯性与可复刻性。此外,AI可高效挖掘、整理、公开负面研究成果,这类失败实验、无效结论长期被学界忽视,但对后续研究规避误区、节约科研资源至关重要,同时海量负面数据也能持续优化AI模型的科研能力,形成正向循环。
生成式人工智能大幅简化了科研文本撰写、数据处理、文献梳理等重复性工作,显著提升科研产出效率,得到广大科研人员认可。《自然》杂志针对1600名科研人员的调查显示,AI可加速数据处理、突破传统算力限制、节约科研时间与成本;欧洲研究委员会(ERC)调查中,85%的受访者认为AI可承接文献综述等劳动密集型科研任务,38%的受访者肯定了AI对整体科学生产力的提升作用(Prillaman, 2024[10])。
相关职业场景实验佐证了AI的生产力赋能价值:针对453名专业从业者的对照实验显示,ChatGPT辅助专业写作可缩短40%的工作时长、提升18%的成果质量,同时缩小从业者能力差距,提升工作公平性,且技术使用意愿具备长期持续性(Noy, 2023[59])。落地到科研领域,AI一方面可支撑传统模式下难以开展的大规模文献分析、复杂系统研究、非结构化数据处理等工作,拓展科研边界;另一方面可解放科研人员精力,使其聚焦核心创新任务,整体提升科研效能,但技术应用带来的成本、误差、同质化等问题,也会抵消部分正向价值。
AI大幅降低了论文撰写与发表门槛,直接推动全球科研论文产出量持续激增(图13.5),同时引发新的学术困境:论文数量快速增长,但核心学术价值、创新质量并未同步提升,学术出版“重量不重质”的问题日益突出。部分机构依托AI搭建“论文工厂”,批量产出低质量、低创新的学术成果,造成学术资源冗余。相关研究证实,论文AI使用程度与预印本数量、领域内卷程度正相关,与论文篇幅、研究深度负相关,大量AI辅助论文仅实现数量增长,未带来实质性知识创新(Liang et al., 2024[4])。
图13.5 科学出版物年度数量
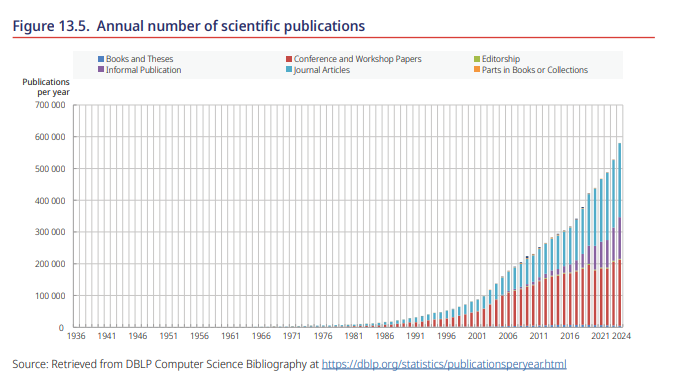
图书与论文、非正式出版物、会议与研讨会论文、期刊文章、编辑身份、书或合集中的章节
每年出版物数量:700,000、600,000、500,000、400,000、300,000、200,000、100,000、0
统计年份:1936-2024
来源:取自DBLP计算机科学书目,https://dblp.org/statistics/publicationsperyear.html
面对AI带来的学术出版变革,全球出版商的监管政策逐步从全面禁止转向精细化规范。早期ICML会议、《科学》杂志全面禁止AI生成文本出版,现阶段行业形成统一差异化规范:仅用于文本编辑、语法优化的AI使用无需披露,用于核心内容生成的AI应用必须主动披露。STM、Wiley、《自然》等主流学术机构均出台对应规范,明确AI使用边界与披露要求(Kwon, 2025[11])。
论文数量爆发式增长,导致同行评审资源严重短缺,评审压力持续攀升(Bergstrom and Bak-Coleman, 2025[62])。AI自动评审技术成为重要解决方案,Liang等人(2024[4])的大规模实证研究证实,GPT-4生成的论文评审意见与人类专家评审重合度极高,自然期刊领域平均重合度达30.85%,ICLR机器学习会议领域达39.23%,优于普通人类评审的一致性水平,且超半数科研人员认为AI评审具备实用价值。但学界对全自动AI评审争议较大,超60%科研人员反对完全自动化评审,Elsevier、美国科学促进会等机构明确禁止AI独立评审,仅允许有限度、可披露的辅助评审(Kwon, 2025[11])。
学术作者身份与科研诚信问题同步凸显。目前全球学术界尚未认可AI为合法合著者,仅2025年出现首例完全由AI撰写的论文成功发表的案例(Sakana.ai, 2025[63])。AI不具备法律主体资格,无法承担学术责任、享有科研权益,认可其作者身份将引发一系列法律与伦理争议。同时,AI可生成高度逼真的合成数据、模拟实验结果,被滥用后极易催生学术不端行为,近年依托AI虚假数据产出的问题论文数量持续增长,严重破坏学术诚信体系(Suchak et al., 2025[64])。
对商业–学术界联系的影响
生成式人工智能的研发与落地需要海量算力、数据、资金与顶尖人才支撑,资源门槛远超普通高校与科研机构,导致核心AI技术、资源、人才高度集中于头部科技企业,形成企业主导、学术界依附的产业格局(Ahmed, Wahed and Thompson, 2023[65]),进一步重塑了产学研合作模式。
这一格局带来双重影响:一方面,企业巨额资金投入推动认知科学、数学等基础学科快速迭代,为科研创新提供强大技术支撑;另一方面,学术界大量AI研究依赖企业融资,导致科研选题、研究方向被商业需求主导,广告、流量等商业目标可能挤压教育研究、公共卫生研究等公益性、基础性研究空间。同时,企业核心技术的保密性与学术界开放共享的科研准则形成冲突,商用AI模型的黑箱特性、数据不透明问题,进一步削弱了AI科研成果的可重复性与公信力,阻碍学术公开化、规范化发展。
生成式人工智能正在推动科学研究发生颠覆性转型,形成区别于传统实验科学、理论科学、模拟科学的全新科研范式,催生“AI驱动的新型科学体系”,学界对这一转型的发展方向与未来形态形成两类核心判断。
生成式人工智能是科研全流程自动化的重要进阶,随着技术持续迭代,未来有望实现科研全链条无人化运作:AI可自主识别研究问题、构思研究假设、设计实验方案、执行实验操作、推导研究结论,完成完整科研闭环。这一场景也被学界称为“AI斩获诺贝尔奖”的终极科研形态(Kitano, 2016[58])。
该范式下将诞生全新的“非人类科学”:科研模型、数据体系、技术逻辑的复杂度将远超人类认知极限,人类无法完整理解、精准把控科研过程与成果。这类科学体系将突破人类认知边界,支撑更复杂的技术创新,但也背离了科学研究的传统使命——深化人类对自然与社会的认知,最终形成“服务于机器、由机器主导”的科研模式。目前这一转型已出现初步迹象,部分科研成果采用机器可读格式发布,突破人类文字传播的认知局限(Stocker et al., 2025[66])。针对这一困境,学界的核心解决方案是研发AI翻译模型,将复杂的机器科研成果转化为人类可理解的语言与逻辑,实现人机认知互通。
传统科学理论的核心价值是数据压缩与规律提炼,依托人类有限的认知与算力,将海量零散的实验数据、现象总结为抽象概念与通用规律,用于预测未知、指导实践。而生成式人工智能具备超强的数据处理与规律挖掘能力,大幅降低了科研对人工理论提炼的依赖,推动科学研究从“理论驱动”向“数据驱动”转型,印证了“理论的终结”这一预判(Anderson, 2008[67])。
学界将AI驱动的大数据科研定义为科学研究第四范式,区别于传统实验范式、模型理论范式、模拟范式,依托海量数据与AI算法直接挖掘潜在规律,无需依赖预设理论框架(Persson, 2025[68])。从现有研究趋势来看,各学科研究范式正逐步向数据化、AI化统一收敛,不同学科的AI辅助研究论文在语义、研究逻辑上高度趋同,传统学科理论体系的边界逐步模糊(Duede, 2024[2])。以计算语言学为例,传统结构化理论分析已逐步被大模型数据驱动分析取代。
这一转型伴随显著科研风险:数据驱动的科研模式会引导学界优先聚焦数据丰富、易落地的应用型问题,弱化对基础性、前瞻性、无明确落地路径的“蓝天科研”的探索,导致基础研究创新不足(Evans et al., 2024[3])。同时,论文产出数量持续增长,但原创性、突破性科研成果增速放缓,出现“科研数量过剩、质量停滞”的生产力悖论,不过这一现象大概率是范式转型的阶段性问题,未来有望依托技术迭代催生全新理论与研究方向。
专栏13.5 人工智能对研究生产力的影响
全球科研生产力已呈现放缓趋势,重大颠覆性发现、核心技术发明的产出效率持续下降,与芯片领域摩尔定律相反,形成“Eroom定律”现象(OECD, 2023[69])。造成这一困境的核心原因包括:一是学科知识体系日益庞大,科研人员需要储备的前置知识不断增加,科研入门与深耕难度提升;二是可简单探索的科学问题已基本攻克,剩余研究对象的复杂度大幅提升;三是科研行政事务日益繁琐,挤占核心研究时间;四是科研激励机制偏向低风险、稳产出的渐进式研究,抑制高风险、高价值的突破性探索。
生成式人工智能可有效缓解前三大困境:依托海量数据处理能力,高效整合梳理庞大的学术知识体系,降低科研认知负担;通过模拟仿真、自动化实验处理复杂科研问题,突破人类算力与操作极限;承接文书撰写、项目申报、数据整理等行政性、重复性工作,解放科研核心精力。但在优化科研激励导向、平衡渐进式创新与突破性探索方面,AI的作用尚不明确,无法从根本上解决科研生态的结构性问题。
结论
生成式人工智能在科研领域的普及速度前所未有,已全面渗透科研全流程:在文本处理层面,成为论文写作、编辑、翻译、文献梳理的核心工具;在科研分析层面,依托专用模型实现复杂科学现象的深度解析;在创新探索层面,逐步具备科研假设构思、实验方案设计的能力,成为稳定可靠的智能科研助手。当前AI对科研模式、产出效率、认知范式的深层影响尚未完全显现,但技术迭代的速度与趋势已明确,新一代掌握AI技术的科研人员将持续推动科研体系全面革新。
全球各国已围绕AI科研应用出台系列扶持与规范政策,覆盖科研资金投入、算力基础设施建设、行业监管等多个维度(OECD, 2023[70]; OECD, 2023[69]),其中科研人才培养是核心核心方向。当前科研领域存在明显的技术代际差距,青年科研人员熟练掌握AI工具,资深科研人员技术适配滞后,同时AI技术人才与领域专业人才存在能力壁垒,导致AI科研成果要么技术先进但领域价值不足,要么贴合领域需求但AI应用深度不够。因此,构建常态化AI科研培训体系、推动跨学科协作、完善资深科研人员终身学习机制,已成为高等教育与科研行业的核心责任。
这一科研转型趋势同样深刻影响教育研究领域。教育科研人员已普遍将AI工具应用于论文撰写、文本润色、数据处理、文献分析等基础工作,通用与专用AI科研工具可全面适配教育研究的知识管理、内容产出需求。尽管现有专业科学生成式模型多聚焦自然科学领域,但技术逻辑可快速迁移至人文社科与教育研究领域。
在研究创新层面,AI可助力教育科研人员建模分析复杂教育现象,挖掘学生学习轨迹、教育发展规律等复杂数据集,实现传统方法无法完成的深度分析;可从海量教育文献中挖掘研究空白、生成全新研究假设,优化教育研究创新体系。在数据应用层面,AI生成的隐私保护型合成数据集,可破解教育数据隐私壁垒,盘活各类未公开的教育行政数据、学习平台数据,同时弥补传统调查数据收集难、样本有限的短板,为教育评估、政策研究、教学优化提供全新数据支撑。
多代理AI模型在教育跨学科研究、教育政策模拟、学生行为仿真、评估体系优化等场景中具备广阔应用前景,可整合心理学、教育学、社会学、经济学等多领域知识,破解教育研究的复杂性、跨学科性难题。同时,自然科学、神经科学、认知科学的AI科研突破,可反向赋能教育研究,助力学界深度解析人类学习机制、大脑发育规律,为教育政策制定、教学模式优化、学生发展干预提供科学依据,推动机器学习与心理学、教育学双向赋能、协同发展(Goddu, 2024[71])。
整体而言,生成式人工智能不会颠覆教育研究的核心本质,而是以工具赋能的形式重塑研究范式。过往各领域的AI科研实践充分证明,**人机协同、人类主导、AI赋能**是AI驱动科研创新的最优模式,严格的人类监督、专业的人工研判、深度的学术思辨,仍是保障教育研究科学性、创新性、严谨性的核心关键。未来教育研究的发展,将依托AI技术实现效率升级、边界拓展、创新赋能,同时坚守人类科研的核心价值与学术底线。
表13.2 生成式人工智能对科学的影响:综合表
| 优势 | 劣势 | 不确定 |
| 获取和处理新型数据:非结构化数据(文本、图像等) | 易产生内容捏造、虚假结论 | 科研创造性的长期发展效果 |
| 高效处理海量科研数据,突破人类算力局限 | 模型输出结果普遍可解释性差 | – |
| 打通跨领域知识壁垒,整合零散学术成果 | 引发论文泛滥,降低学术质量门槛 | – |
| 解析复杂科研系统,挖掘深层规律 | 导致科研选题同质化,降低学术多样性 | – |
| 自动化处理行政、重复性科研任务,提升整体生产力,聚焦核心创新 | 可提升部分研究的可重复性,但整体可靠性仍存疑 | – |
与其他科学领域一样,学习或学生路径等复杂现象的建模(例如 Pardos 和 Borchers,2026[16])已经开始,由于人工智能探索大型复杂数据集的新可能性,它可能会继续扩展。这可能允许新类型的分析。人们还可以想象,GenAI 工具将能够从研究文献中提取假设,由于能够管理更多数据并可能生成新数据,从而改进其中一些假设。
生成很大程度上复制原始数据集的合成隐私保护数据集也是 GenAI 提供的一种新可能性。这确实允许探索和分析出于隐私原因未共享、链接(或创建)的数据集。教育研究将有可能更广泛地获取管理数据和数字学习平台收集的数据。合成数据集需要仔细评估,以确保它们正确复制原始数据集的统计属性并真正保护隐私。由于教育研究的一部分依赖于调查数据,而调查数据据说越来越难以收集,因此用模拟数据增强这些数据的可能性也开辟了新的可能性,尽管目前还不清楚这种途径的前景如何。虽然标准化测试的开发和分析现在通常包括生成模拟答案(即模拟学生),但这种技术是否可以扩展到其他科目仍然存在争议。人工智能多主体模型是科学研究中一个有前途的途径,也可以用于教育研究:它们可以帮助解决受益于跨学科研究的问题,或者涉及模拟社会主体反馈的问题,就像政策研究和制定中的情况一样。
最后但并非最不重要的一点是,教育研究可能会受益于新的科学 GenAI 工具所带来的其他领域的进步。人们确实可以想象,如果有适当的激励,新的研究可以探索学习时大脑的化学反应,或者神经科学和认知科学将为儿童的生物发展提供新的见解,从而为教育研究和政策提供信息。机器学习作为一门学科与心理学之间存在明显的融合,尤其是具有双向知识流的发展心理学,其中心理学为机器学习提供有关训练方法和架构的信息,而机器学习为心理学提供了其假设的测试平台(例如参见 Goddu,2024[71])。
虽然很难预测 GenAI 将如何融入教育研究结构,不是作为一个主题,而是作为一种工具,但迄今为止它在其他领域的使用的一个明显教训是,成功的 GenAI 支持的研究需要人类的严格监督,并且通常对应于增强模型而不是替代模型。