第十二章:标准化评估中的生成式人工智能:与Alina von Davier的对话
提高项目设计的生产力
OECD:许多人工智能工具在评估方面非常有效,有时甚至比生成式人工智能更好。然而,我们想探索生成人工智能可以提供哪些新的可能性。我们对两个主要领域感兴趣:生成式人工智能如何帮助更有效地执行传统评估任务(例如,标准化评估的项目生成)以及如何实现不同的、更好的评估。或许我们可以从第一个方面开始?
Alina von Davier:为了进行评估,在 Duolingo,我们端到端地利用人工智能,但不是孤立的:它只是对我们的流程做出贡献。例如,在人类专家设计出物品原型后,我们使用生成式人工智能大规模生成物品。内容专家在设计阶段与人工智能工程师和心理测量学家合作,以确保新项目类型的设计在操作环境中可行。一旦初始项目设计完成并且我们对此感到满意,人工智能工程师和科学家就会定义在线交付所需的项目显示,并创建将大规模生成多个项目的脚本。之后,这些项目将由人类专家审查其质量、公平性和全球管理的适当性。这已成为主流流程。我们创建了项目工厂,这是一个人与机器协作的完整系统。我要强调的是,一开始就涉及大量工作。当您第一次为特定项目类型设置 GenAI 系统时,需要非常高水平的专业知识和相当大的努力。这就是主要工作所在:进行设置并确定哪些有效,哪些无效。然而,一旦该设置完成,与人类发育相比,效率会提高十倍。就速度和成本而言,这是令人难以置信的。我们仍然非常保守,并继续使用人工来审查每一个项目,但我们计划探索如何提高效率。
图12.1
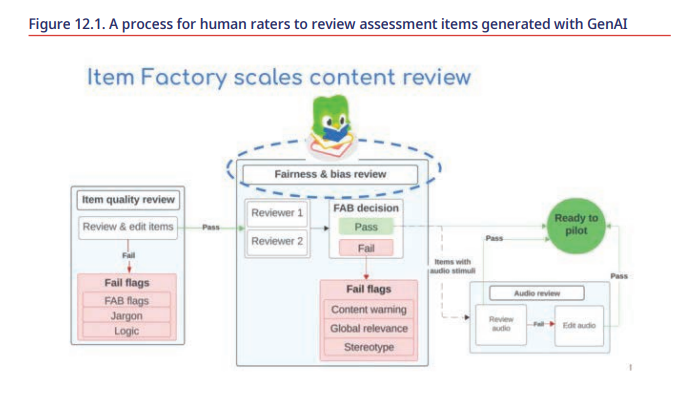
提高写作和口语技能的评估
OECD:除了提高传统评估设计的生产力之外,我们如何利用 GenAI 来创新评估人们知识和技能的方式?
Alina von Davier:例如,在我们的 Duolingo 英语测试中,我们还有 GenAI 的另外两种应用:一种用于写作任务,另一种用于口语任务。 2024年4月,我们启动了新的写作任务,其工作原理如下。我们提供一个提示,例如“请写关于主题 X – 你有 y 分钟”,在他们完成作业后,人工智能会实时干预,分析迄今为止编写的文本,并将其与我们为该特定项目创建的一组主题进行比较。然后,人工智能充当同伴或教授,建议通过涵盖新的子主题来继续写作,例如询问“你也可以写这个吗?”。在 GenAI 之前,此类项目的这种类型的交互功能是不可能的:它可以更接近现实生活中的任务,从而提供更高的真实性——这是大多数评估都存在的问题。
最近,即 2025 年 7 月,我们推出了一项交互式自适应口语任务,在此期间,考生与人工智能代理进行对话。生成方面主要涉及生成代理的话语。虽然它不是实时代理并且受到极大限制,但它允许我们创建交互性,就像写作项目的情况一样。这两个例子使用生成式人工智能进行与以前不同的评估。如果没有技术这是不可能的
写作任务只涉及人工智能的一次干预。你收到提示,你开始写作,然后人工智能进来并要求你写更多关于特定主题的内容。相反,口语任务是对话,涉及多种交互。管理这些多重交互是充满挑战的。这很困难,因为需要嵌入人工智能才能“理解”人所说的内容。当考生不是所测试语言的母语时,这意味着他们有各种口音和能力,需要做大量工作来确保人工智能能够理解每个人的演讲,对其进行评估,然后为该人选择适当的回应。所以,它实际上比写作任务更难实现。据我所知,这是第一次在数百万考生的高风险评估中包含如此互动和自适应的口语任务。
OECD:这两项任务的目的是什么?您想要评估(或实现)什么?
Alina von Davier:这种设计方法的核心目标有两个:真实性和对考生的支持。在此之前,你可能只是说“写10分钟”,而不是在写作过程中间评价他们写的内容,然后鼓励考生继续写。这里的关键区别在于,在现实生活中,人们经常会让别人审阅自己的写作,并在如何继续方面获得建议。我们也采用同样的做法,这就是互动性方面。第二,我们的目标也是帮助考生。当我们为写作任务提供初始提示时,它通常有多个可能的写作方向。我们希望鼓励考生涵盖他们尚未涉及的其他方面,帮助他们成为更好的写作者,并给予他们展示不同主题写作能力的机会。最终,我们评估的是他们作为外语的英语写作质量。
关于口语任务,目前没有任何其他高风险测试使用纯技术驱动的互动口语。之前,测试可能会提供一个提示,你听并回答,然后听另一个内容并回答,但它既不是互动的,也不是适应性的。我们的口语任务既是适应性的,也是互动性的。例如,如果考生的英语水平不是很高,人工智能代理会调整并参与更简单的对话,这在以前是不可能的。另一项具有真正双向访谈的英语水平测试是雅思英语测试,但他们是由人来进行的。作为考生,你必须预约,前往考试中心,与人交谈。我们正试图保持这种对话,但替换掉前往中心的差旅安排。对考生来说,traveling to a centre and take a test delivered by human interviewers(前往中心参加由人工面试官进行的测试)是一个极其昂贵且困难的过程。我们的测试是持续的,可以随时随地参加,因此对于这种交付模式来说,基于技术的解决方案更有意义。此外,人类评分存在固有问题,例如光环效应:如果考生在一个问题上表现得好,考官可能会将这种积极印象转移到评估后续问题中。
经合组织:这些任务的有效性水平如何?我假设你们已经测试了它们对参加测试者的表现,效果好吗?与人类评分员相比效果如何?最后,在这种高度约束的人工智能场景中,结合你们的适配要求(如适应性、拓展对话主题等),你们如何将传统人工智能与生成式人工智能结合?具体的运作方式是什么?
Alina von Davier:相关设置完成后,大规模生成这类测试任务的效率极高,且产出质量十分出色,专业人员无法区分其与人工生成的任务差异。
关于您的第二个问题:我们所运用的技术不只有生成式人工智能,同时会调用其他类型的人工智能模型与心理测量模型,各类人工智能程序协同配合工作。我们自主编写模型与运行脚本,拥有大量可调用通用人工智能、生成式人工智能实现不同应用场景的脚本。需要明确的是,生成式人工智能只是人工智能的其中一种类型,我们的系统会同时运用多种人工智能技术。
以我前文提到的口语任务为例,其中部分核心环节仅能依靠生成式人工智能完成,比如实时听懂考生表述、快速完成内容评估。而后续的脚本运行环节,即智能代理筛选适配答案、输出口语回应的过程,并非单纯依靠生成式人工智能,同时融合了心理测量学技术。也就是说,部分专属任务由生成式人工智能独立完成,其余环节则依托其他人工智能模型与计算心理测量学技术实现。针对写作任务,在我们的规模化运营模式下,文本实时审阅的工作只能由生成式人工智能完成。但所有技术环节都嵌套在专属脚本与程序体系中,生成式人工智能不会独立运行,我们不会单纯向生成式人工智能输入指令、要求其独立完成工作,而是通过专属脚本设计标准化提示词,再输入生成式人工智能执行任务,整个运作流程十分复杂。这也是我前文提到的,搭建这套体系需要大量专业知识与时间积累的原因。
经合组织:在完成写作、口语任务考核后,后续流程是什么?是衔接其他测试任务,还是直接生成考试分数?你们是否采用人工智能为考生评分?
Alina von Davier:是的,评分工作由人工智能结合心理测量学技术完成,但核心依托机器学习模型,而非生成式人工智能。其中,口语评分的发音评估环节,需要借助生成式人工智能实现。我们的技术体系涵盖多种人工智能形式,并非仅依赖大型语言模型(LLMs)。例如,我们会运用自动语音识别(ASR)系统完成声音处理、语音转文本、文本转语音等基础操作。因此,我们的评分、监考环节均已实现人工智能全覆盖,也就是我所说的全流程智能化。同时,我们会结合专业心理测量模型核算最终分数,并校验分数的可靠性与有效性。
我们下一项依托生成式人工智能升级的核心功能是测评反馈,将率先落地在写作测试板块,目前该功能已基本研发完成,初期主要应用于测试练习场景。另一项优化方向是适度放宽人工智能口语代理的运行约束,但前提是必须保障测评的可比性,这是标准化高风险测试的核心要求。若完全放开大型语言模型的自主运行权限,极易出现测评偏差,同一考生可能在不同场次获得差异化测评回应。这类不确定性在普通场景中可以接受,但绝对不适用于高风险标准化测试,这也是我们设置多重运行约束的核心原因。当然,我们可以通过微调约束条件,提升测试场景的真实性,同时严格守住高质量考试所需的测评准确性与可比性底线。
经合组织:非常感谢您分享人工智能与生成式人工智能在当代标准化评估中的应用模式。
Alina von Davier:不客气。大家可以登录多邻国英语测试官网,查看平台内的练习中心,里面开放了各类测试真题,全部免费公开,有兴趣深入了解的人群都可以自行查阅体验。
高风险评估和下一步
经合组织:针对高风险测试,考试评分方式一直存在诸多争议。业界普遍认为,传统人工智能在测评准确性、结果一致性上优于生成式人工智能。传统机器学习模型的测评精度更高,但灵活性不足,且训练耗时久、成本高,一旦测试任务迭代,往往需要重新训练模型。而生成式人工智能的适配性更强,能够快速适配新场景、降低迭代成本,但测评精度相对欠缺。这一特性使其适用于普通测评场景,却难以直接适配高风险测试场景。您是否认同这一观点?未来这一现状是否会有所改变?结合您的实操经验,能否分享一下相关看法?
Alina von Davier:首先我想强调,用好生成式人工智能的核心,是掌握正确的使用方法。随意套用通用提示词,绝对无法实现高质量的标准化测评,这并非生成式人工智能的正确应用方式。很多人存在认知误区,认为只需简单下达指令,人工智能就能完美完成测评任务,但实际并非如此。面对市场上对生成式人工智能过于片面的正面或负面评价,我们都需要保持审慎态度,不必全盘采信,因为目前大多数人尚未积累足够的生成式人工智能实操经验。
这是我现阶段最核心的观察:大众普遍认为生成式人工智能操作简单、交互灵活,但高质量标准化测评的落地,远比大众认知的复杂。只要掌握科学的提示词设计方法、搭建合理的运行架构,生成式人工智能可以输出全维度高质量测评结果。在教授生成式人工智能用于试题研发的过程中,我一直提倡“分而治之”的应用思路。简单来说,不要试图通过单一提示词完成所有测评任务。
举个例子,若需要为八年级学生设计配套阅读段落与考题,不要将段落生成、题目设计、难度适配等所有需求整合在一个提示词中,最终的产出效果会极差。我建议拆分任务、分步落地:先生成测评段落,审核校验段落质量,确认达标后,再针对性设计配套考题。这种分步操作的模式,产出质量会大幅提升,但目前尚未普及。很多人习惯一键整合所有需求,简单测试后便判定生成式人工智能效果不佳,这是非常片面的。因此,我始终建议大家保持理性,对所有极端化的正面、负面评价,保持质疑与求证的态度。
经合组织:这个观点很有启发。目前已有大量最新研究文献表明,想要让生成式人工智能的评分质量,达到传统机器学习模型的同等水准,需要优化完善大量提示词设计工作。
Alina von Davier:在评分环节,我们主要依托自主研发的机器学习模型,仅部分场景融合生成式人工智能组件。自研模型的核心优势,除了精准度可控,更重要的是能保障测评结果的可比性。如果生成式人工智能在不同时段,对同一篇答卷给出差异化评分,就会破坏测评的可比性与可复制性,而这两项指标是标准化测评可靠性的核心基础。
生成式人工智能的评分精度并非固定,完全取决于使用方式。例如,在作文评分场景中,若为生成式人工智能提供标准化、精细化的评分细则(与人工评分细则完全一致),同时配套足量标杆案例,其完全可以实现高质量评分。但最终效果会受任务复杂度、测评用途的影响,存在一定差异化。
目前所有人工智能测评技术,无论是试题生成还是智能评分,都具备较强的场景专属属性。部分基础模块可以通用,但核心模型均需要适配具体测评任务,每切换一类测评场景,都需要重新校验模型适配性,无法直接通用。
同时,我们搭建了多层级质检体系与多重过滤机制,所有未达标的试题、测评结果均不会对外上线。我们配套搭建了多套人工智能质检系统,实时监控测评质量。首款自研工具AQuAA,全称评估质量保证分析系统,融合多项机器学习模型与心理测量学技术,可作为智能预警系统,实时分析平台测评数据,一旦监测到异常数据,会第一时间发出预警,提示工作人员核查处理。后续迭代的AQuAP系统,全称题库质量保证分析系统,同样后台实时运行,全程监控题库试题状态,避免试题难度突发波动、异常表现等问题,保障题库稳定性,该系统同样以机器学习为核心技术支撑。目前,我们正在研发面向考生维度的AQuATT系统,进一步完善全维度测评质量管控体系。
经合组织:非常感谢您分享人工智能与生成式人工智能在当代标准化评估中的应用模式。
Alina von Davier:不客气。大家可以登录多邻国英语测试官网,查看平台内的练习中心,里面开放了各类测试真题,全部免费公开,有兴趣深入了解的人群都可以自行查阅体验。
延伸阅读文献
[1] Burstein, J., G. T. LaFlair, K. Yancey, A. von Davier, and R. Dotan (2024), “Responsible AI for Test Equity and Quality: The Duolingo English Test as a Case Study”.
[2] Hao, J., A. von Davier, V. Yaneva, S. Lottridge, M. von Davier, D. J. Harris (2024), “Transforming Assessment: The Impacts and Implications of Large Language Models and Generative AI”, Educational Measurement: Issues and Practice, Vol. 43/2, pp. 16-29, https://doi.org/10.1111/emip.12602.
[3] von Davier, A. (2024), How Will AI Change Adaptive Testing?
[4] von Davier, A. and J. Burstein (2024), “AI in the Assessment Ecosystem: A Human–Centered AI Perspective”, in Intelligent Systems Reference Library, Artificial Intelligence in Education: The Intersection of Technology and Pedagogy, Springer Nature Switzerland, Cham, https://doi.org/10.1007/978-3-031-71232-6_6.
[5] von Davier, A., A. Runge, Y. Park, Y. Attali, J. Church, and G. LaFlair (2024), “The item factory”, Machine Learning, Natural Language Processing, and Psychometrics.